scRNA-单细胞转录组学习笔记-15-利用scRNAseq包学习scater
刘小泽写于19.8.9-第三单元第五讲:利用scRNAseq包学习scater 笔记目的:根据生信技能树的单细胞转录组课程探索smart-seq2技术相关的分析技术 课程链接在:http://jm.grazy.cn/index/mulitcourse/detail.html?cid=53
复习
我们之前在 第14篇笔记中学习了scRNAseq包的数据,知道了它可以分成4组:pluripotent stem cells 分化而成的 neural progenitor cells (NPC,神经前体细胞) ,还有 GW16(radial glia,放射状胶质细胞) 、GW21(newborn neuron,新生儿神经元) 、GW21+3(maturing neuron,成熟神经元) ,其中NPC和其他组区别较大。并且使用常规的操作进行了初步的探索,但是毕竟是单细胞数据,就会有专业的包对它进行处理,于是这次就来介绍第一款:scater包(https://www.bioconductor.org/packages/release/bioc/html/scater.html)
首先来看官网教程
亲测,6个小时就能学完Scater官方提供的三个教程
这个包是EMBL和剑桥大学发布的,是为分析单细胞转录组数据而开发,它包含了一些特性:
它需要利用
SingleCellExperiment这个对象,就是这个东西( 来自Bioconductor-workshop):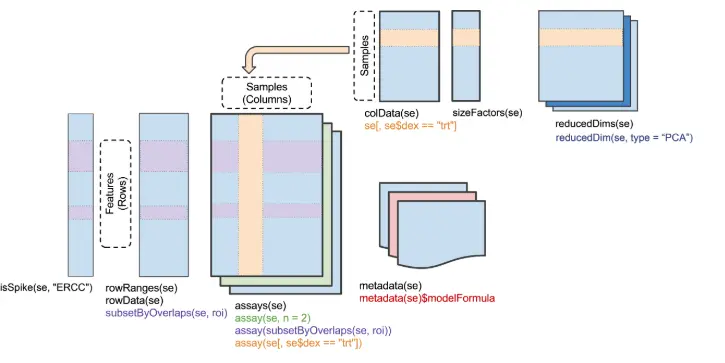
可以导入非比对工具 kallisto and Salmon 得到的定量结果
计算了大量的QC指标,方便过滤
可视化方面做得不错,设计了大量的函数(尤其针对质控),并且功能如其名
从2017年7月,scater包就改变了整体架构,从之前的
SCESet对象更改成了更多人都在用的SingleCellExperiment,使用Bioconductor 3.6 (2017.10发布)安装的包,都会是SingleCellExperiment对象。如果要更迭也不难,官方给了许多解决方案,例如:toSingleCellExperiment函数、updateSCESet函数
假设现在有一个包含表达量信息的矩阵,其中包含的feature信息可以是gene, exon, region, etc.
第一步 创建一个SingleCellExperiment对象 (官网 24 May 2019)
需要注意的是,官方友情提示,在导入对象之前,最好是将表达量数据存为矩阵;
如果是较大的数据集,官方建议使用
chunk-by-chunk的方法,参考 Matrix 包,然后使用readSparseCounts函数,有效减少内存使用量(因为它可以不将大量的0表达量放进内存);如果是导入10X的数据,使用 DropletUtils 包的
read10xCounts函数即可,它会自动生成一个SingleCellExperiment对象对于非比对定量工具,scater也提供了
readSalmonResults、readKallistoResults支持两款软件,它的背后利用的是 tximport
rm(list = ls())
Sys.setenv(R_MAX_NUM_DLLS=999) ##在R3.3版本中,只能有100个固定的动态库限制,到了3.4版本以后,就能够使用Sys.setenv(R_MAX_NUM_DLLS=xxx)进行设置,而这个数字根据个人情况设定
options(stringsAsFactors = F)
# 使用包自带的测试数据进行操作
library(scater)
data("sc_example_counts")
data("sc_example_cell_info")
> dim(sc_example_counts)
[1] 2000 40
> sc_example_counts[1:3,1:3] # 基因表达矩阵
Cell_001 Cell_002 Cell_003
Gene_0001 0 123 2
Gene_0002 575 65 3
Gene_0003 0 0 0
> sc_example_cell_info[1:3,1:3] # 样本注释信息
Cell Mutation_Status Cell_Cycle
Cell_001 Cell_001 positive S
Cell_002 Cell_002 positive G0
Cell_003 Cell_003 negative G1
# 接下来就是构建对象(日后只需要复制粘贴替换即可)
example_sce <- SingleCellExperiment(
assays = list(counts = sc_example_counts),
colData = sc_example_cell_info
)
> example_sce
class: SingleCellExperiment
dim: 2000 40
metadata(0):
assays(1): counts
rownames(2000): Gene_0001 Gene_0002 ... Gene_1999 Gene_2000
rowData names(0):
colnames(40): Cell_001 Cell_002 ... Cell_039 Cell_040
colData names(4): Cell Mutation_Status Cell_Cycle Treatment
reducedDimNames(0):
spikeNames(0):
注意到上面构建对象时使用了counts = sc_example_counts这么一个定义,官方也推荐,使用counts作为导入表达矩阵的名称,这样会方面下面的counts函数提取;另外还支持exprs、tmp、cpm、fpkm这样的输入名称
> str(counts(example_sce))
int [1:2000, 1:40] 0 575 0 0 0 0 0 0 416 12 ...
- attr(*, "dimnames")=List of 2
..$ : chr [1:2000] "Gene_0001" "Gene_0002" "Gene_0003" "Gene_0004" ...
..$ : chr [1:40] "Cell_001" "Cell_002" "Cell_003" "Cell_004" ...
调用或修改行或列的metadata比较方便:
# 默认调用/修改 列,所以example_sce$whee就是新增一列metadata
example_sce$whee <- sample(LETTERS, ncol(example_sce), replace=TRUE)
colData(example_sce)
# 如果对行新增一行metadata(注意这里rowData和原来的矩阵没有关系,它操作的是一些注释信息)
rowData(example_sce)$stuff <- runif(nrow(example_sce))
rowData(example_sce)
除此以外,还有一些比较复杂的函数:例如isSpike 对spike-in操作,sizeFactors 是进行标准化时对细胞文库大小计算的结果、reducedDim 对降维结果(reduced dimensionality results)操作
另外,对这个对象取子集也是很方便的,例如要过滤掉在所有细胞中都不表达的基因:
# 过滤不表达基因
keep_feature <- rowSums(counts(example_sce) > 0) > 0
example_sce <- example_sce[keep_feature,]
第二步 (可选)计算一堆表达统计值 (官网 24 May 2019)
如果要计算CPM值,之前一直使用log2(edgeR::cpm(dat)+1)进行计算,这个包自己做了一个函数:
# 计算的CPM值存到example_sce对象的标准命名(cpm)中去
cpm(example_sce) <- calculateCPM(example_sce)
另外还可以提供标准化:normalize函数,它计算得到:log2-transformed normalized expression values
# 总体计算方法是:dividing each count by its size factor (or scaled library size, if no size factors are defined), adding a pseudo-count and log-transforming (翻译一下:将每个count值除以size factor,记得之前edgeR进行标准化就计算了这么一个值,它就是为了均衡各个样本文库差异;如果没有size factor,也可以对文库大小进行归一化),接着加一个值(例如1,为了不让log为难),最后log计算
example_sce <- normalize(example_sce) # 结果保存在logcounts中
assayNames(example_sce)
## [1] "counts" "cpm" "logcounts"
注意:表达矩阵的标准命名中,
exprs和logcounts是同义词,它是为了和老版本的scater函数兼容:identical(exprs(example_sce), logcounts(example_sce)) ## [1] TRUE
另外,我们也可以根据需要创建一个和原始count矩阵同样维度的新矩阵,存储在assay中
# 比如创建一个判断的矩阵,看看原来count矩阵中的每个值是不是都大于0,结果是一堆的逻辑值
assay(example_sce, "is_expr") <- counts(example_sce)>0
还有,calcAverage函数可以计算样本标准化以后,各个基因的平均表达量(如果样本还没进行标准化,那么它首先会计算size factor)
head(calcAverage(example_sce))
## Gene_0001 Gene_0002 Gene_0003 Gene_0004 Gene_0005 Gene_0006
## 305.551749 325.719897 183.090462 162.143201 1.231123 187.167913
第三步 数据可视化(官网 24 May 2019)
重点包含这几方面:
plotExpression:画出一个或多个基因在细胞中的表达量水平plotReducedDim:(计算或)绘制降维后的坐标- 其他的QC图
# 创建并标准化
library(scater)
data("sc_example_counts")
data("sc_example_cell_info")
example_sce <- SingleCellExperiment(
assays = list(counts = sc_example_counts),
colData = sc_example_cell_info
)
example_sce <- normalize(example_sce)
example_sce
## class: SingleCellExperiment
## dim: 2000 40
## metadata(1): log.exprs.offset
## assays(2): counts logcounts
## rownames(2000): Gene_0001 Gene_0002 ... Gene_1999 Gene_2000
## rowData names(0):
## colnames(40): Cell_001 Cell_002 ... Cell_039 Cell_040
## colData names(4): Cell Mutation_Status Cell_Cycle Treatment
## reducedDimNames(0):
## spikeNames(0):
先来绘制基因表达相关的图:
通过这种方式,可以方便检查差异分析、拟时序分析等等的feature结果;它默认使用标准化后的logcounts值,当然,可以定义exprs_values参数来修改
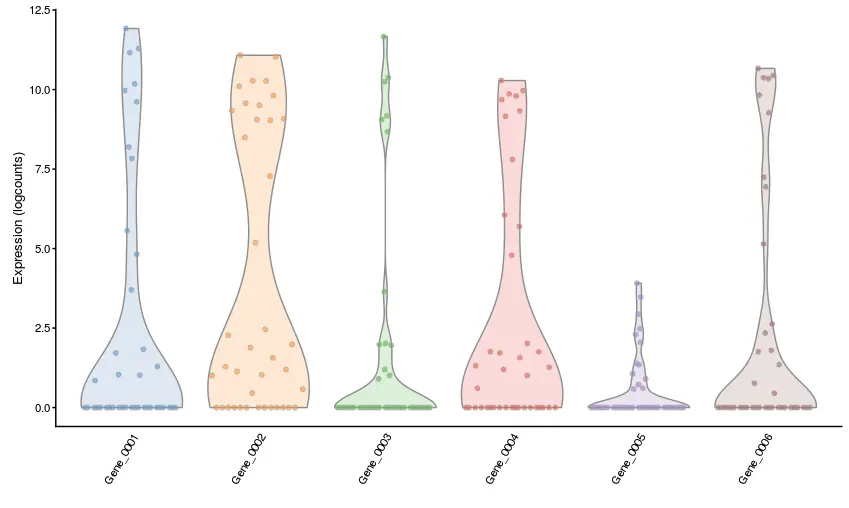
# 最简单的图
# 默认使用标准化后的logcounts值
plotExpression(example_sce, rownames(example_sce)[1:6])
# 增加分组信息:定义x是一个离散型分组变量
plotExpression(example_sce, rownames(example_sce)[1:6],
x = "Mutation_Status", exprs_values = "logcounts")
# 查看绘制的x这个metadata
> colData(example_sce)$Mutation_Status
[1] "positive" "positive" "negative" "negative" "negative" "negative" "positive" "positive"
[9] "negative" "positive" "negative" "negative" "positive" "negative" "negative" "negative"
[17] "positive" "negative" "negative" "negative" "positive" "positive" "negative" "positive"
[25] "negative" "positive" "positive" "negative" "positive" "negative" "negative" "positive"
[33] "positive" "negative" "positive" "negative" "negative" "negative" "negative" "negative"

不难看到,它是将细胞先根据x = "Mutation_Status"进行了分组,然后对6个基因绘制了表达分布图
这个
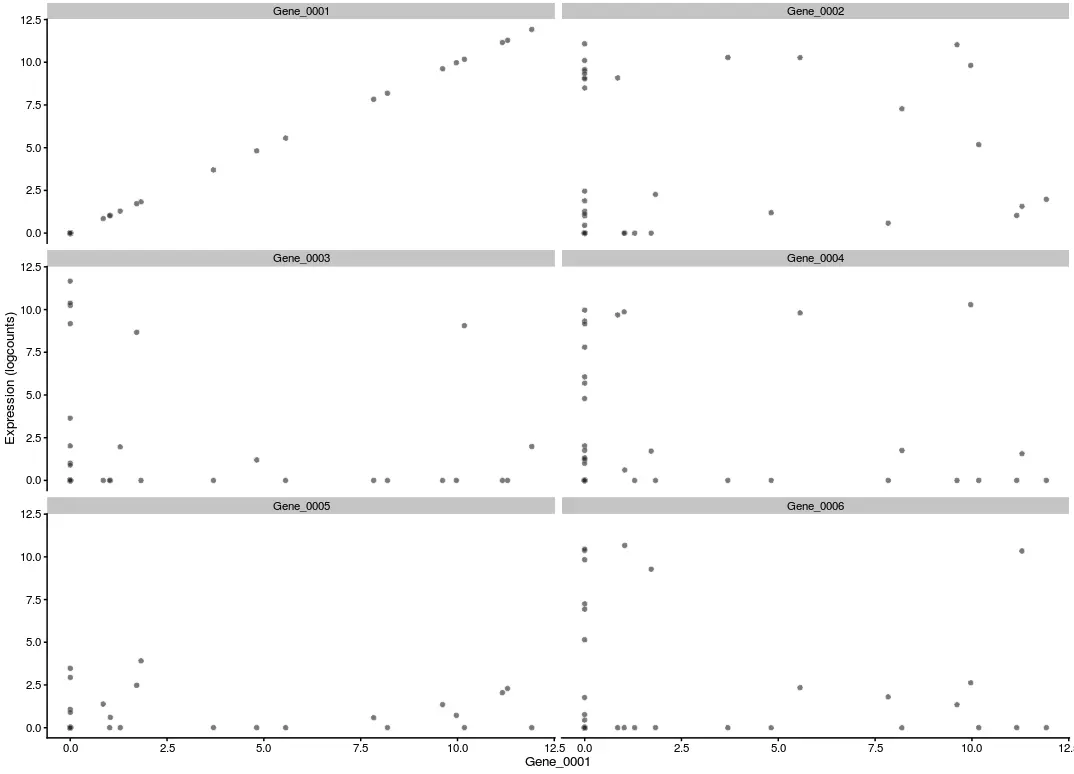
x参数的设置很讲究:它的英文含义是 covariate to be shown on the x-axis,定义了x轴上的协变量。简单理解,就是x轴上按照什么来定义,如果x是一个分类的离散型变量(比如这里的positive、negative),那么x轴就是为了分组,结果就是小提琴图;如果x是一个连续的变量(比如下面👇要演示的某个基因表达量),那么x轴就是为了看数值的变化,结果就是散点图
# 定义x是一个连续型变量
plotExpression(example_sce, rownames(example_sce)[1:6],
x = "Gene_0001")
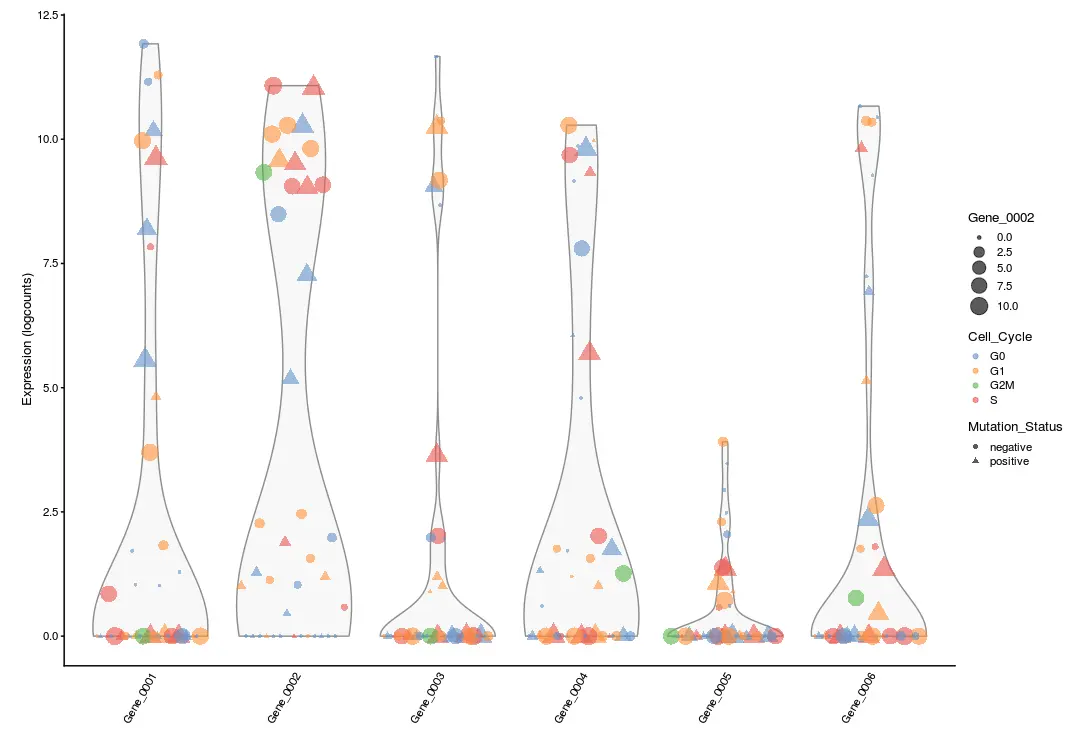
可以自定义颜色、形状、大小的区分,例如:
plotExpression(example_sce, rownames(example_sce)[1:6],
colour_by = "Cell_Cycle", shape_by = "Mutation_Status",
size_by = "Gene_0002")
# 利用两个metadata:Cell_Cycle(区分颜色)、Mutation_Status(区分形状)
# 利用一个表达量指标:Gene_0002(区分大小)
上面这张图可以再加上之前说的
x参数,还是按照Mutation_Status进行x轴分组
# 添加中位线、x轴分组
plotExpression(example_sce, rownames(example_sce)[7:12],
x = "Mutation_Status", exprs_values = "counts",
colour = "Cell_Cycle", show_median = TRUE,
xlab = "Mutation Status", log = TRUE)

再来绘制降维相关的图:
SingleCellExperiment对象中包含了reducedDims接口,其中存储了细胞降维后的坐标,可以用reducedDim、reducedDims函数获取
关于这两个函数的不同:使用
?reducedDim就能获得 ForreducedDim, a numeric matrix is returned containing coordinates for cells (rows) and dimensions (columns).For
reducedDims, a named SimpleList of matrices is returned, with one matrix for each type of dimensionality reduction method.
降维首先利用PCA方法:
# runPCA结果保存在sce对象的PCA中。默认情况下,runPCA会根据500个变化差异最显著的feature的log-count值进行计算,当然这个数量可以通过ntop参数修改。
example_sce <- runPCA(example_sce)
> reducedDimNames(example_sce)
[1] "PCA"
> example_sce
class: SingleCellExperiment
dim: 2000 40
metadata(1): log.exprs.offset
assays(2): counts logcounts
rownames(2000): Gene_0001 Gene_0002 ... Gene_1999 Gene_2000
rowData names(0):
colnames(40): Cell_001 Cell_002 ... Cell_039 Cell_040
colData names(4): Cell Mutation_Status Cell_Cycle Treatment
reducedDimNames(1): PCA
spikeNames(0):
注:runPCA源代码在此:https://rdrr.io/bioc/scater/src/R/runPCA.R
任何的降维结果,都能用plotReducedDim函数作图
plotReducedDim(example_sce, use_dimred = "PCA",
colour_by = "Treatment", shape_by = "Mutation_Status")
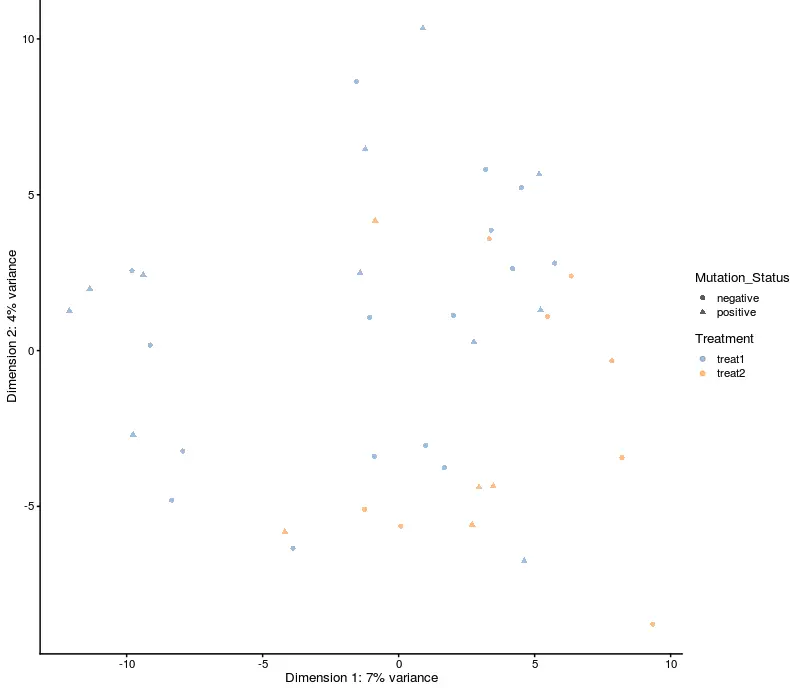
然后可以利用表达量添加颜色、大小分组
# 看特定基因在PCA过程中起到的作用
plotReducedDim(example_sce, use_dimred = "PCA",
colour_by = "Gene_1000", size_by = "Gene_0500")

除了使用
plotReducedDim,还能使用plotPCA自己去生成,但前提还是要使用PCA的计算结果;如果检测不到PCA的计算坐标,这个函数会自己runPCA计算一遍。尽管如此,还是推荐先进行计算,再作图。因为有时候我们需要利用一个数据集做出多张不同的图(就像上面👆一样),但是每做一张图这个函数都要运行一遍太费时间,如果已经计算好,那么它就能直接调用,十分方便
# 最简单的plotPCA
plotPCA(example_sce)
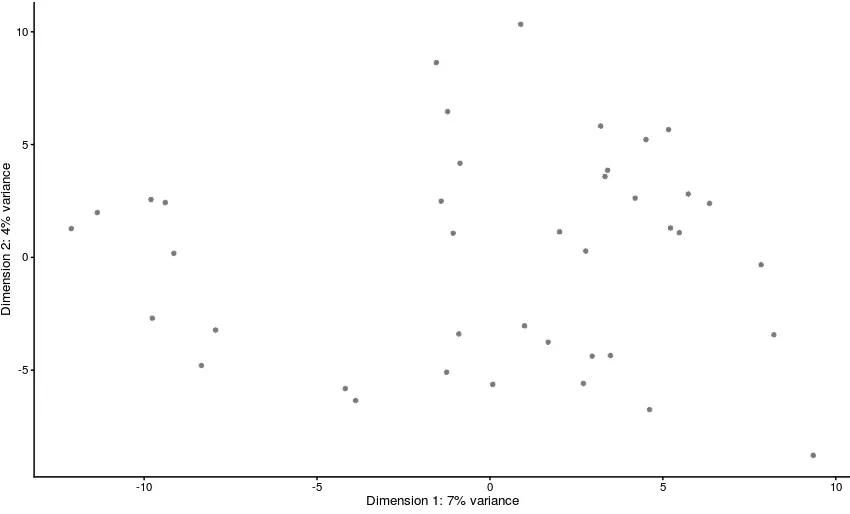
它也可以像plotReducedDim一样,定义颜色、大小
plotPCA(example_sce, colour_by = "Gene_0001", size_by = "Gene_1000")
另外我们可以自己选择进行PCA的数据,例如使用自己的feature_control(例如使用的ERCC spike-in ),来看看数据中是否存在技术误差而导致差异
# 默认情况下,runPCA会根据500个变化差异最显著的feature。这里定义 feature_set可以覆盖默认设置
# 看官方描述:eature_set Character vector of row names, a logical vector or a numeric vector of indices indicating a set of features to use for PCA. This will override any \code{ntop} argument if specified.
example_sce2 <- runPCA(example_sce,
feature_set = rowData(example_sce)$is_feature_control)
plotPCA(example_sce2)
还可以绘制多个主成分:
example_sce <- runPCA(example_sce, ncomponents=20)
# 绘制4个成分
plotPCA(example_sce, ncomponents = 4, colour_by = "Treatment",
shape_by = "Mutation_Status")
接着使用t-SNE(t-distributed stochastic neighbour embedding)降维:
关于tsne这个流行的算法,有必要了解一下:
tsne的作者Laurens强调,可以通过
t-SNE的可视化图提出一些假设,但是不要用t-SNE来得出一些结论,想要验证你的想法,最好用一些其他的办法。t-SNE中集群之间的距离并不表示相似度 ,同一个数据上运行
t-SNE算法多次,很有可能得到多个不同“形态”的集群。但话说回来,真正有差异的群体之间,不管怎么变换形态,它们还是有差别关于perplexity的使用:(默认值是30) 如果忽视了perplexity带来的影响,有的时候遇到
t-SNE可视化效果不好时,对于问题无从下手。perplexity表示了近邻的数量,例如设perplexity为2,那么就很有可能得到很多两个一对的小集群。
有的时候会出现同一集群被分为两半的情况,但群间的距离并不能说明什么,解决这个问题,只需要跑多次找出效果最好的就可以了
引用自: https://bindog.github.io/blog/2018/07/31/t-sne-tips/ 很好的tsne可视化:https://distill.pub/2016/misread-tsne/
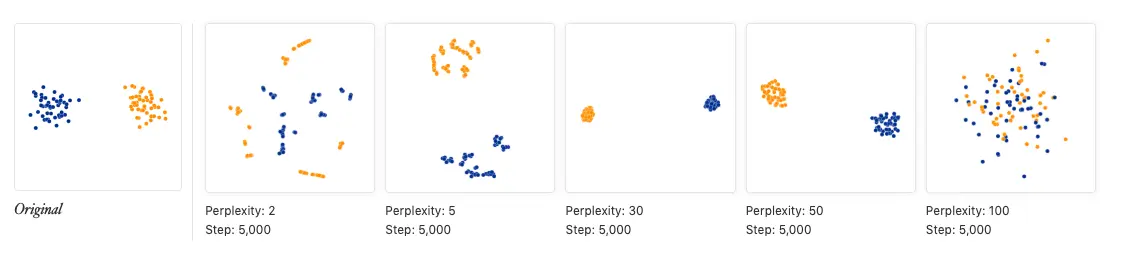
和PCA类似,先runTSNE,再plotTSNE。另外注意,为了重复结果要设置随机种子,因为tsne每次映射的坐标结果都不同。官方强烈建议,使用不同的随机种子和perplexity数值出图
# Perplexity of 10 just chosen here arbitrarily.
set.seed(1000)
example_sce <- runTSNE(example_sce, perplexity=10)
plotTSNE(example_sce, colour_by = "Gene_0001", size_by = "Gene_1000")
还可以使用diffusion maps降维:
example_sce <- runDiffusionMap(example_sce)
plotDiffusionMap(example_sce, colour_by = "Gene_0001", size_by = "Gene_1000")
第四步 质控(官网 24 May 2019)
作为关键的一步,值得关注!
质控主要包含以下三步:
- 质控并过滤细胞
- 质控并过滤feature(基因)
- 对实验的一些变量进行质控
首先登场的是calculateQCMetrics函数
它对每个细胞和feature信息计算了大量的统计指标,分别存在colData和rowData中,这个函数默认对count值进行计算,但是也可以通过参数exprs_values进行修改
example_sce <- calculateQCMetrics(example_sce)
> colnames(colData(example_sce)) # 样本质控
[1] "Cell" "Mutation_Status"
[3] "Cell_Cycle" "Treatment"
[5] "is_cell_control" "total_features_by_counts"
[7] "log10_total_features_by_counts" "total_counts"
[9] "log10_total_counts" "pct_counts_in_top_50_features"
[11] "pct_counts_in_top_100_features" "pct_counts_in_top_200_features"
[13] "pct_counts_in_top_500_features"
> colnames(rowData(example_sce)) # feature质控
[1] "is_feature_control" "mean_counts" "log10_mean_counts" "n_cells_by_counts"
[5] "pct_dropout_by_counts" "total_counts" "log10_total_counts"
另外可以此时设置对照:对feature(基因)信息来讲,可以添加ERCC、线粒体基因等信息,对细胞来讲,可以添加empty wells、 visually damaged cells等信息,然后接下来计算的QC指标就会包含这些信息
example_sce <- calculateQCMetrics(example_sce,
feature_controls = list(ERCC = 1:20, mito = 500:1000),
cell_controls = list(empty = 1:5, damaged = 31:40))
all_col_qc <- colnames(colData(example_sce))
all_col_qc <- all_col_qc[grep("ERCC", all_col_qc)]
# 取出的就是ERCC的指标
> all_col_qc
[1] "total_features_by_counts_ERCC" "log10_total_features_by_counts_ERCC"
[3] "total_counts_ERCC" "log10_total_counts_ERCC"
[5] "pct_counts_ERCC" "pct_counts_in_top_50_features_ERCC"
[7] "pct_counts_in_top_100_features_ERCC" "pct_counts_in_top_200_features_ERCC"
[9] "pct_counts_in_top_500_features_ERCC"
如果定义了control组,那么计算的结果还会有一类:就是将control汇总在一起计算的
feature_control和cell_control;非control的汇总在一起得到endogenous和non_control(这几个名称在我们命名数据集时应该避开)
关于细胞质控的几个重点关注结果
total_counts:每个细胞中总表达量(文库大小)
total_features_by_counts:细胞中超过规定阈值(默认是0)的feature数量
pct_counts_X:属于feature control组(也就是这里的X)的表达量占比
如果使用的不是counts值而是其他矩阵,比如tpm,那么结果中也会将counts替换为tpm
关于feature质控的几个重点关注结果
- mean_counts:基因/feature的平均表达量
- pct_dropout_by_counts:基因在细胞中表达量为0的细胞数占比(该基因丢失率)
- pct_counts_Y:属于cell control组的表达量占比
- log10_mean_counts:归一化 log10 scale
- n_cells_by_counts:多少个细胞表达了该基因
绘图函数–检测高表达基因(plotHighestExprs)
默认显示前50个基因。图中每一行表示一个基因,每个线条(bar)表示这个基因在不同细胞的表达量(可以想象成把基因表达量的箱线图转了一下)。圆圈是每个基因表达量的中位数,并且在图中经过了排序。
plotHighestExprs(example_sce, exprs_values = "counts")
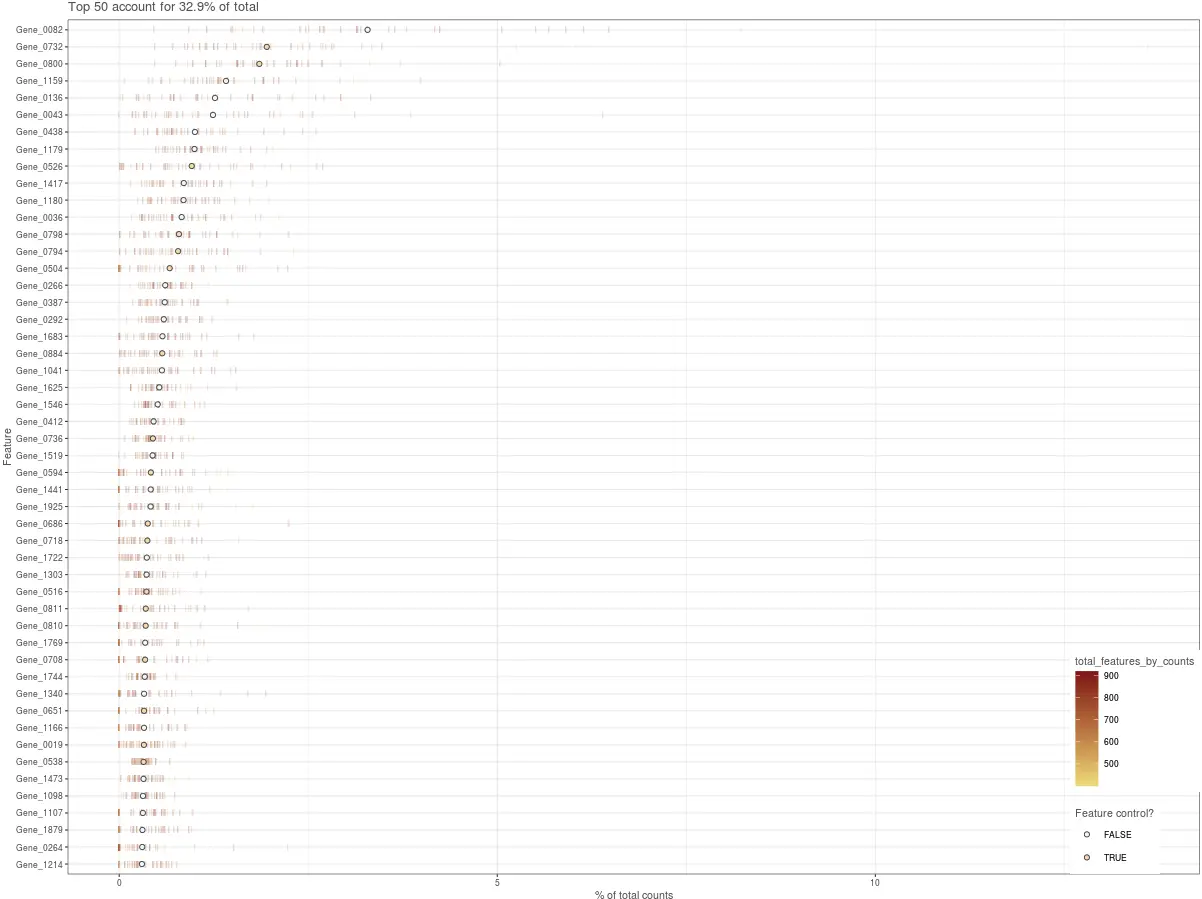
我们期待这个图会给出符合常理的结果,比如:线粒体基因、actin、ribosomal protein、MALAT1,另外或许有少量的ERCC spike-in在这里有显示。ERCC数量少还可以,但是如果在top50基因中,ERCC占比过多,就表示加入了太高浓度的外源RNA,高ERCC含量与低质量数据相关,通常是排除的标准。除此以外,还有可能会见到一些假基因或预测的基因名,这表明可能比对过程出现了问题
绘图函数—表达频率比均值(plotExprsFreqVsMean)
表达频率指的是非0表达量的细胞数量(当然这个表达阈值也可以自己定义);理论上,对于大多数基因来说,它应该和平均表达量正相关
plotExprsFreqVsMean(example_sce)
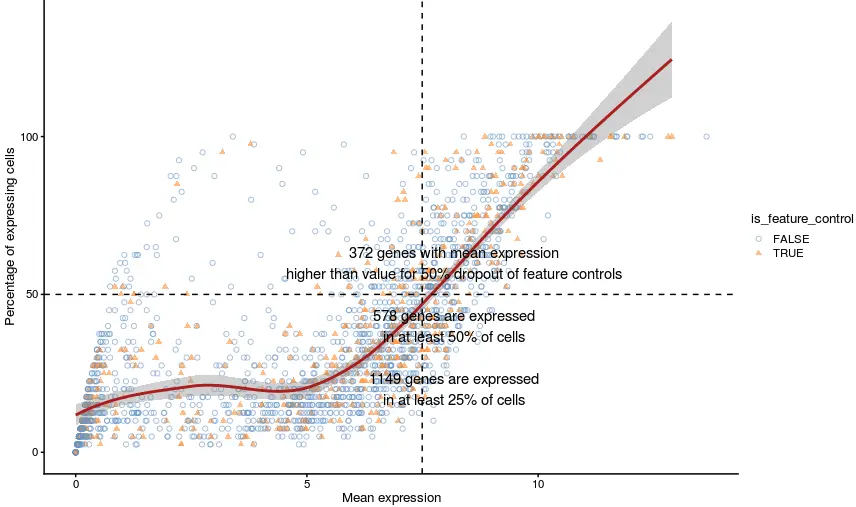
但其实图中也能看出一些异常:
例如表达量均值很低,但覆盖的细胞数量由非常高(图中左上部),可能的原因是:比对到一些假基因(pseudo-genes )(假基因是原来的能翻译成蛋白的基因经过各种突变导致丧失功能的基因),然后造成了一个假象
一般来说,结尾是P1等字眼的都是假基因(如:KRAS–>KRASP1);根据https://www.genenames.org/download/statistics-and-files/数据,目前存在13311个假基因
又如,表达量均值很高,但细胞数量却很少(图中右下部),可能因为PCR扩增偏好性(或者存在罕见的细胞群)
绘图函数—总feature表达量 vs feature control占比(plotColData)
这个函数是对细胞进行质控的,原理很简单,就是看看细胞中实际表达量高还是feature control(例如ERCC)的占比高。如果实际表达量高,feature control占比小的话,就说明细胞质量不错;相反,就说明存在blank and failed cells的情况。我们最后就是看散点主要集中在哪边(右下部效果较好)
plotColData(example_sce, x = "total_features_by_counts",
y = "pct_counts_feature_control", colour = "Mutation_Status") +
theme(legend.position = "top") +
stat_smooth(method = "lm", se = FALSE, size = 2, fullrange = TRUE)

绘图函数—表达量累计贡献图(plotScater)
这个函数先在表达量最高的基因中选一部分(默认是500个),然后从高到低累加,看看它们对每个细胞文库的贡献值如何。它将不同细胞的不同基因表达分布绘制出来,就像芯片数据或bulk转录组数据每个样本做一个箱线图,来看基因表达量分布。但是由于单细胞数据样本太多,没办法全画出箱线图。
为了看不同细胞的表达量差异,可以利用colData中的数据将细胞分类;
默认使用counts值,但是只要在assays存在的表达矩阵,就可以在exprs_values参数中自定义
plotScater(example_sce, block1 = "Mutation_Status", block2 = "Treatment",
colour_by = "Cell_Cycle", nfeatures = 300, exprs_values = "counts")
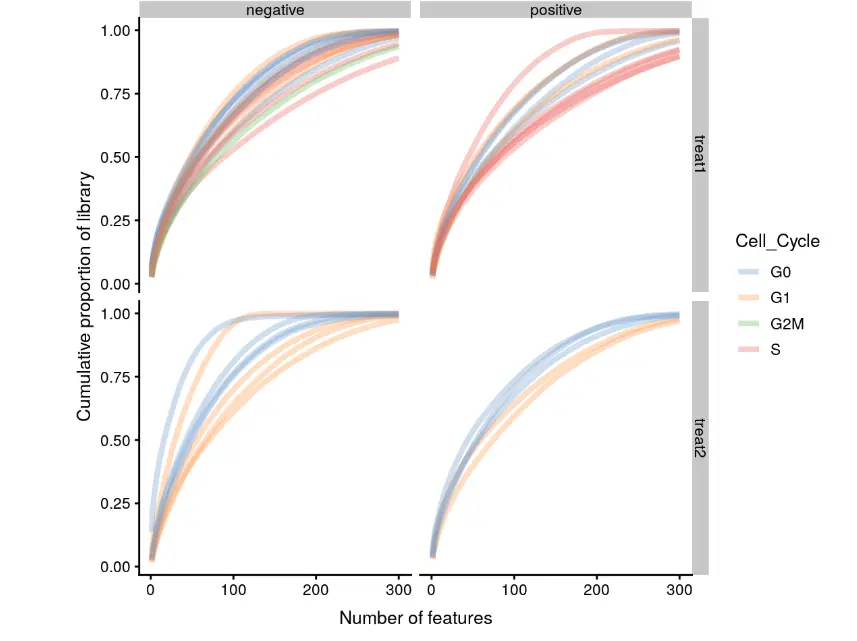
这个图在处理不同批次细胞时就可以很清楚地看到它们之间的差异
绘图函数—QC结果两两比较
# 比较feature的属性
plotRowData(example_sce, x = "n_cells_by_counts", y = "mean_counts")
# 比较样本的属性
p1 <- plotColData(example_sce, x = "total_counts",
y = "total_features_by_counts")
p2 <- plotColData(example_sce, x = "pct_counts_feature_control",
y = "total_features_by_counts")
p3 <- plotColData(example_sce, x = "pct_counts_feature_control",
y = "pct_counts_in_top_50_features")
# 最后可以组合
multiplot(p1, p2, p3, cols = 3)
第五步-1 对细胞过滤(官网 24 May 2019)
对列取子集
列就是细胞样本,最简单的方法就是直接按照类似数据框的操作:
example_sce <- example_sce[,1:40]
另外,还提供了filter函数(受到dplyr包的同名函数启发)
filter(example_sce, Treatment == "treat1")
设置条件来过滤
例如设置细胞的总表达量不能低于100,000,总表达基因数不能少于500
keep.total <- example_sce$total_counts > 1e5
keep.n <- example_sce$total_features_by_counts > 500
filtered <- example_sce[,keep.total & keep.n]
dim(filtered)
## [1] 2000 37
除此以外,还有一种更灵活的方式:isOutlier函数,它设置的是距离中位数差几个MAD值(绝对中位差 median absolute deviations),超过设定值的被认为是离群点(outlier),它们就会被舍去。例如设置过小的离群点为:log count值低于中位数的3个MAD值。
可以看到,这个函数没有“一刀切”,可以根据测序深度、spike-in的影响、细胞类型等进行调整。 如何设置阈值是一门学问,官方也推荐看看:https://bioconductor.org/packages/release/workflows/html/simpleSingleCell.html
keep.total <- isOutlier(example_sce$total_counts, nmads=3,
type="lower", log=TRUE)
filtered <- example_sce[,keep.total]
根据QC结果来过滤
比如用一个PCA图:
example_sce <- runPCA(example_sce, use_coldata = TRUE,
detect_outliers = TRUE)
plotReducedDim(example_sce, use_dimred="PCA_coldata")
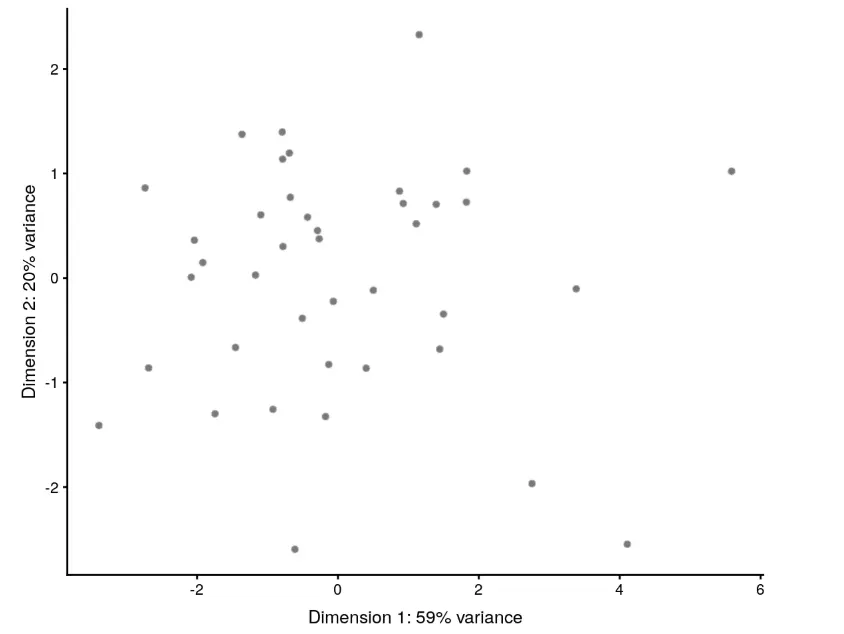
结果就会在example_sce对象中增加一个outlier的接口,我们可以这样看:
summary(example_sce$outlier)
## Mode FALSE
## logical 40
第五步-2 对feature过滤(官网 24 May 2019)
最简单的方法是用自带的函数(当然,也可以在构建对象前就过滤好):
keep_feature <- nexprs(example_sce, byrow=TRUE) >= 4
example_sce <- example_sce[keep_feature,]
dim(example_sce)
## [1] 1753 40
第六步 探索不同实验因素对表达量的影响
# 一般是要先标准化
example_sce <- normalize(example_sce)
plotExplanatoryVariables(example_sce)
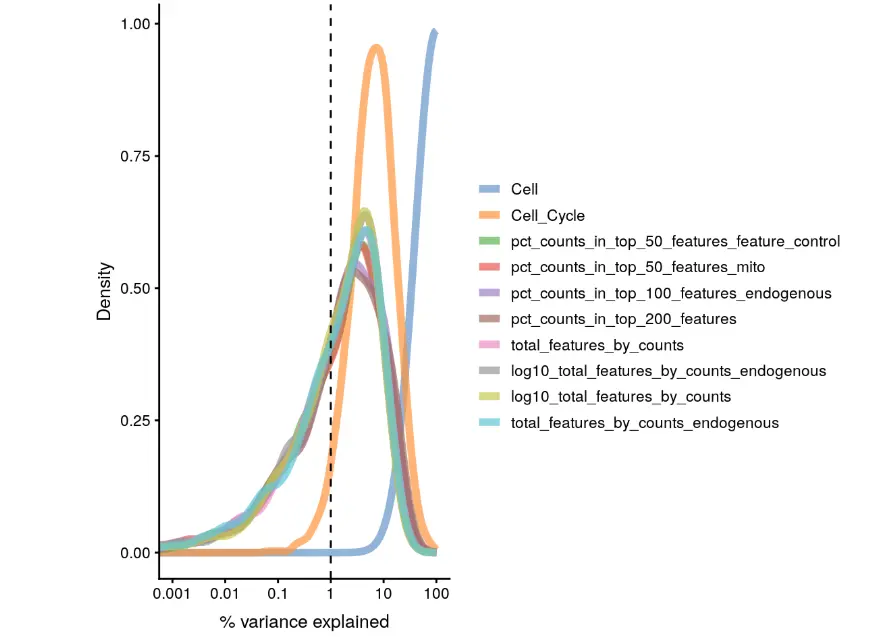
结果中的每条线都表示一个影响因子,当然我们也可以选择一部分
plotExplanatoryVariables(example_sce,
variables = c("total_features_by_counts", "total_counts",
"Mutation_Status", "Treatment", "Cell_Cycle"))
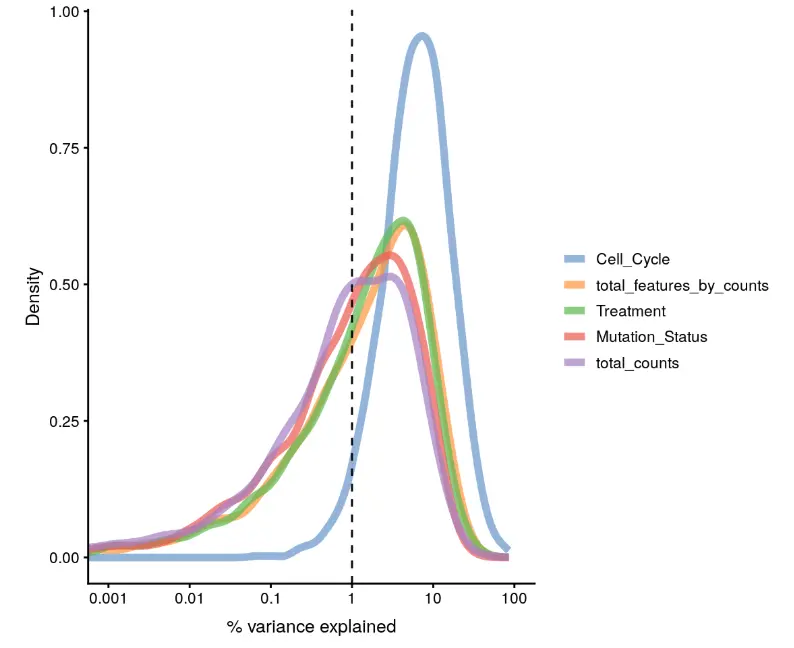
结果看到:因为是测试小数据的缘故,total_counts 和 total_features_by_counts 对基因表达变化差异贡献很高(接近10%),真实数据中这两个占比应该在1-5%之间
第七步 去除技术误差
Scaling normalization
可选的有normalize函数,官方还强烈推荐了 友包scran的computeSumFactors、computeSpikeFactors函数
Batch correction
Unlike scaling biases, these are usually constant across all cells in a given batch but different for each gene.
可以用limma的removeBatchEffect函数
library(limma)
batch <- rep(1:2, each=20)
corrected <- removeBatchEffect(logcounts(example_sce), block=batch)
assay(example_sce, "corrected_logcounts") <- corrected
另外还推荐了:scran的mnnCorrect函数(之前也介绍过:https://www.jianshu.com/p/b7f6a5efed85)
好,上面的官网教程结束,下面继续对scRNAseq这个包中的四组细胞类型进行scater操作
回到scRNA数据
首先载入数据
library(scRNAseq)
## ----- Load Example Data -----
data(fluidigm)
# 得到RSEM矩阵
assay(fluidigm) <- assays(fluidigm)$rsem_counts
ct <- floor(assays(fluidigm)$rsem_counts)
> ct[1:4,1:4]
SRR1275356 SRR1274090 SRR1275251 SRR1275287
A1BG 0 0 0 0
A1BG-AS1 0 0 0 0
A1CF 0 0 0 0
A2M 0 0 0 33
> table(rowSums(ct)==0)
FALSE TRUE
17096 9159
# 样本注释信息
pheno_data <- as.data.frame(colData(fluidigm))
# 然后做scater的数据
sce <- SingleCellExperiment(
assays = list(counts = ct),
colData = pheno_data
)
> sce
class: SingleCellExperiment
dim: 26255 130
metadata(0):
assays(1): counts
rownames(26255): A1BG A1BG-AS1 ... ZZEF1 ZZZ3
rowData names(0):
colnames(130): SRR1275356 SRR1274090 ... SRR1275366 SRR1275261
colData names(28): NREADS NALIGNED ... Cluster1 Cluster2
reducedDimNames(0):
spikeNames(0):
简单质控
sce <- calculateQCMetrics(sce)
然后是过滤
基因层面
# 进行一个标准化
exprs(sce) <- log2(calculateCPM(sce) + 1)
genes <- rownames(rowData(sce))
genes[grepl('^MT-',genes)] # 检测线粒体基因
genes[grepl('^ERCC-',genes)] # 检测ERCC
# 假入有线粒体基因或ERCC,就可以加入feature control组中
sce <- calculateQCMetrics(sce,
feature_controls = list(ERCC = grep('^ERCC',genes)))
colnames(rowData(sce)) # 查看信息
# 只过滤那些在所有细胞都没有表达的基因
keep_feature <- rowSums(exprs(sce) > 0) > 0
# table(keep_feature)
sce <- sce[keep_feature,]
# sce
细胞层面
# 细胞质控属性非常多
colnames(colData(sce)) # 查看信息
可视化同上
学习SC3包
library(SC3) # BiocManager::install('SC3')
sce <- sc3_estimate_k(sce) # 预估亚群(24个)
metadata(sce)$sc3$k_estimation
rowData(sce)$feature_symbol <- rownames(rowData(sce))
# 接下来正式运行,kn参数表示的预估聚类数
# 我们这里自定义为4组(因为已知真正就是4组,实际上需要探索)
kn <- 4 # 还可以设置3、5看看结果
sc3_cluster <- "sc3_4_clusters"
Sys.time()
sce <- sc3(sce, ks = kn, biology = TRUE) # 运行会很慢
Sys.time()
# 最后进行可视化--比较先验分类和SC3的聚类的一致性
sc3_plot_consensus(sce, k = kn, show_pdata = c("Biological_Condition",sc3_cluster))
# 最后进行可视化--表达量信息
sc3_plot_expression(sce, k = kn, show_pdata = c("Biological_Condition",sc3_cluster))
# 最后进行可视化--可能的marker基因
sc3_plot_markers(sce, k = kn, show_pdata = c("Biological_Condition",sc3_cluster))
# PCA上展示SC3的聚类结果
plotPCA(sce, colour_by = sc3_cluster )