064-R的知识迭代之基础操作
刘小泽写于18.12.10
生信必备三大件:生物、统计、技术,我想要借助R来学习统计学知识,因为平时使用R比较频繁,理解起来应该也会更快一些。先来一次R的知识迭代,更新下知识库
先看一些比较基础的R操作
这其中有一些是我之前没有学习到的,第一次get感觉超级有用
我们一般都会查询陌生的函数如何使用,会用到
help()。默认状态下,help()函数只会在载入加载过的程序包中搜索,如果想在所有包中进行搜索,又不想先加载它,可以用help("xx", try.all.packages=TRUE);如果已经知道函数在哪个包中,可以用help("xx", package="yy")数据直接编辑:借助
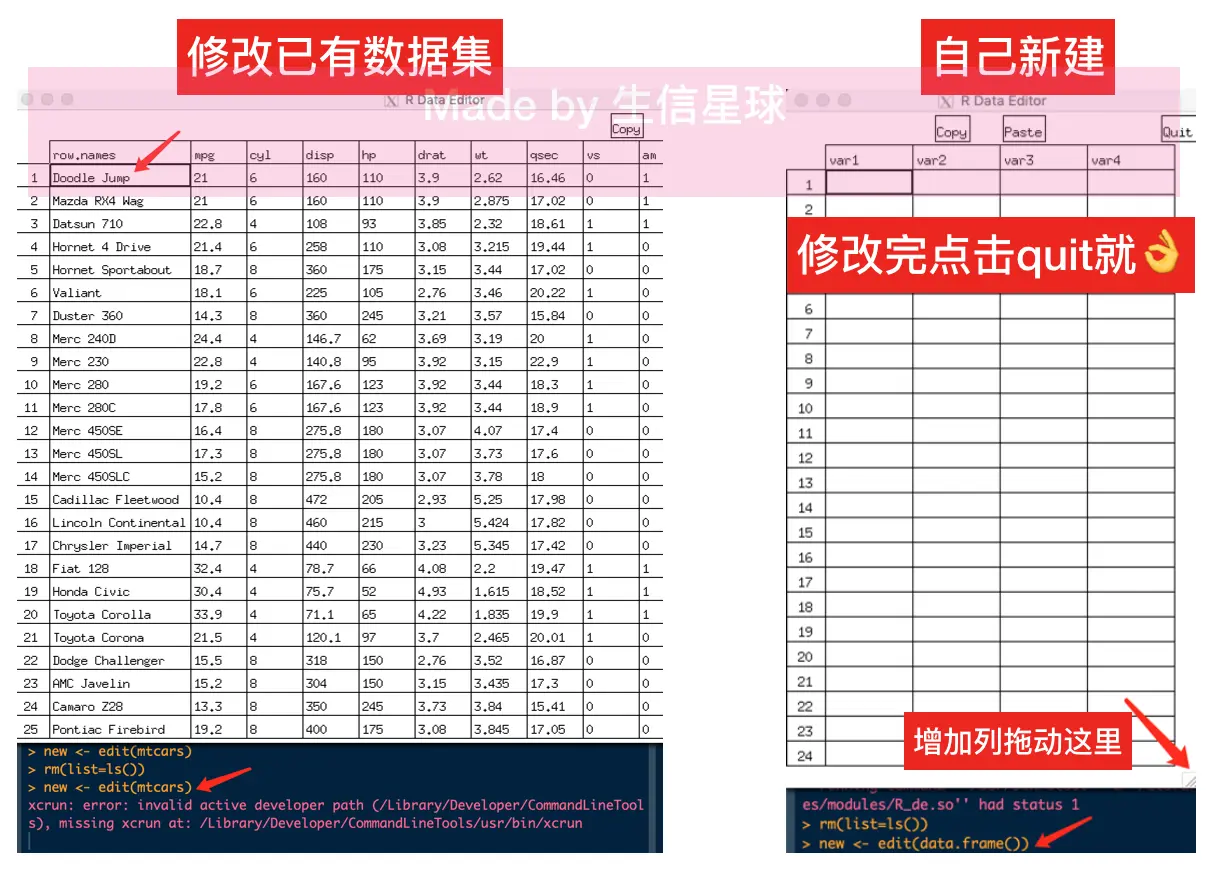
edit()函数,我们可以直接在R中进行数据修改(这个功能我其实一直在寻找,但最近才发现,这样就不用导出后修改然后再导入R了)。 例如,我们要修改mtcars这个数据集,但是为了避免修改原有的数据集,可以新保存到一个变量如new <- edit(mtcars),然后修改完点quit就好; 如果想在现有数据集基础上修改,不想新建,那么可以用fix(mtcars); 创建一个新的数据集,再向其中填充数据new <- edit(data.frame()),默认创建两列,然后拖动右下角就出现更多的列;Windows是可以直接使用edit的,Mac的话需要先安装XQuartz这个工具
如果想研究数据集中的某个变量,比如mtcars中的mpg,可以使用
mtcars$mpg,但是如果还需要别的变量,那还是多敲几遍mtcars$;其实可以先将数据集激活,放到环境中,什么时候想提取,就直接输变量名就好了,比如先attach(mtcars),就是将mtcars当做当前数据集,然后想调用mpg变量直接输入mpg就好;不想用了就detach(mtcars)不同数据,不同目的,不同分析:
属性数据
例如mtcars中的cyl数据(记录气缸数)是属性变量。先激活mtcars数据集,然后使用
table(cyl)得到cyl中的三个值:4,6,8和相应的频数;还可以barplot画直方图barplot(table(cyl)),直接barplot(cyl)也能画,但是分组信息就体现不出来,失去了意义数值型数据
这一类在统计分析中经常用到,例如mtcars中的mpg变量就是数值型数据;另外不同函数反映的意义也是不同的。
作图可以画直方图
hist(mpg),箱线图boxplot();统计分析可以分析均值
mean();计算截掉5%的均值mean(mpg, trim=.05);按分组变量cyl来计算mpg的分组均值tapply(mpg, cyl, mean);计算cyl为6的mpg的均值mean(mpg[cyl == 6 ]);计算常用分位数(包括极小、极大、中位数、两个四分位数)quantile(mpg)或者fivenum(mpg)或者summary(mpg);计算四分位数的极差IQR(mpg);标准差sd(mpg);中位绝对离差(median absolute deviation)mad(mpg)探索二元关系
1 拟合线性回归,例如
> z <- lm(cyl~mpg) > z # 结果 Call: lm(formula = cyl ~ mpg) Coefficients: (Intercept) mpg 11.2607 -0.2525 # 线性回归截距11.26,斜率-0.252 相关系数:考察回归拟合的好坏,例如相关系数R可以用
cor(cyl, mpg)表示,更常用的R^2^ 就能计算出来为0.726,表示数据变化的72.6%可以用气缸数(cyl)与每加仑的英里数(mpg)表示3 残差分析:残差是估计值与观测值的偏差
z <- lm(cyl ~ mpg) #将回归分析的结果作为对象保存在lm.res中 lm.resids <- resid(z) # 提取残差向量 plot(lm.resids) # 画个散点图 hist(lm.resids) # 画个直方图,是否为钟形? qqnorm(lm.resids) # QQ图(Quantile-Quantile Plots)是否落在直线上? # 都是为了检验数据集分布假设是否有效
了解下R的对象
对象属性
R运行都是靠对象,所有的对象都有两个内在属性:类型和长度
类型包括四种:数值型、字符型、复数型、逻辑型(T/F/NA),用函数mode()查看。另外不管什么类型的数据,缺失值都是用NA(Not Available)表示,不是数值用NaN(Not a Number)表示;
数值型:数值太大用指数形式表示,如
N <- 2e20,Inf表示正无穷字符型:输入时要加上双引号,如果要在其中继续引用双引号的话,可以用
\进行转义;或者直接用单引号> x <- "Double quotes \" delimitate R's strings." # 双引号 > x <- 'Double quotes " delimitate R\'s strings.' # 单引号 >x [1] "Double quotes \" delimitate R's strings." # 在R中显示的状态[注意这里在R中显示的还带着转义符,其实显示出来是没有的] > cat(x) Double quotes " delimitate R's strings. # 实际上的状态
长度是对象中元素的数目,用length()查看
对象类别
只有数据框和列表支持多种对象并存;因子只有两种类型
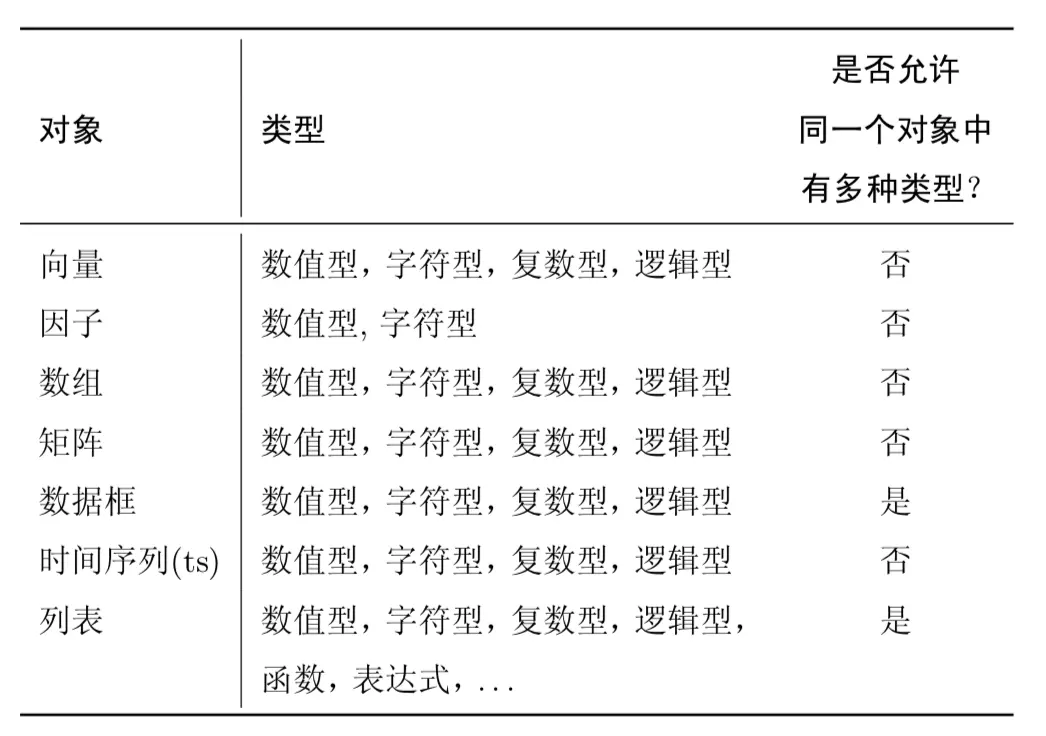
向量是一个变量的取值;因子是一个分类变量;数组是一个k维的数据表;矩阵是数组的特例【数组或者矩阵的所有元素都是一种】;数据框是一个或几个向量/因子构成,并且它们必须等长,可以是不同的类型;列表可以包含任何类型的对象(也可以列表包含列表)
浏览对象
利用ls()可以查看当前在内存中的对象,但是这个函数只列出了对象名,并且是所有的;
想要查看名称中含有某个指定字符(如x)的对象,可以指定pattern:ls(pat = "x");
想要看以某个字母开头的对象,可以利用ls(pat = "^x") ;
如果想看所有对象的详细信息呢?ls.str()
删除对象
rm(x,y)删除对象x和yrm(list=ls())删除所有对象rm(list=ls(pat="^x"))删除所有x开头的对象
了解下R的向量
建立向量
数值型向量
向量没规律:
c()向量的规律比较简单:
seq()或“:”> 1:10 # 1 2 3 4 5 6 7 8 910 > 1:10-1 # 0 1 2 3 4 5 6 7 8 9 > 1:(10-1) # 注意有括号与上面没有的区别 # 1 2 3 4 5 6 7 8 9 > z <- seq(1,5,by=0.5) # 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 > z <- seq(1,10,length=11) # 1.0 1.9 2.8 3.7 4.6 5.5 6.4 7.3 8.2 9.1 10.0向量的规律比较复杂:
rep()> z <- rep(2:5,2) # 2 3 4 5 2 3 4 5 > z <- rep(2:5,each=2) # 2 2 3 3 4 4 5 5通过键盘输入向量
scan()> z <- scan() 1: 1 2 3 4 5 6 7: # Read 6 items > z # 1 2 3 4 5 6
字符型向量
注意引号在输入时应该写作:\" ;paste()可以连接多个参数成为字符串,其中如果有数值,那么数值会被强制转为字符串;默认空格分割各个字符,使用sep=自定义
逻辑型向量
TRUE、FALSE可以简写成T、F;如果转换为数值,FALSE为0,TRUE为1
因子型向量
利用factor()建立
factor(x, levels = sort(unique(x), na.last = TRUE),
labels = levels, exclude = NA, ordered = is.ordered(x))
levels 指定因子水平(缺省值是向量x中不同的值);
labels 指定水平名称;
ordered是逻辑型选项,表示因子水平是否有顺序
- 字符型因子转为数值型因子【反之亦然】
> a <- c("x","y","z","x")
> a
[1] "x" "y" "z" "x"
> levels(a) <- c(1,2,3)
> a
[1] 1 2 3 1
Levels: 1 2 3
产生规则的因子序列,利用
gl(k,n),k是水平数,n是重复数;另外还有两个选项,length指定总共数据个数,label指定每个水平名称> gl(2,3) [1] 1 1 1 2 2 2 Levels: 1 2 > gl(2,3,length=10) [1] 1 1 1 2 2 2 1 1 1 2 Levels: 1 2 > gl(2,3,labels = c("x","y")) [1] x x x y y y Levels: x y
向量提取
这里简单说下根据逻辑值提取
# 例如x向量是这样的
> x <- c(20, 15, 11, 6)
> x>10 # 这个仅仅是判断,返回的也是F/T
[1] TRUE TRUE TRUE FALSE
> x[x>10] # 提取大于10的元素
[1] 20 15 11
> x[ x < 15 & x > 10] # 限定多个提取条件
[1] 11
> y <- x[!is.na(x)] # 找到x中的非缺失值
> z <- x[(!is.na(x))&(x>0)] # 非负非缺失值
了解下R的矩阵 Matrix
相比于数组,矩阵使用频率更高,构建矩阵使用matrix
> x <- matrix(1:3, 2, 3) # 默认按列填充
> x
[,1] [,2] [,3]
[1,] 1 3 2
[2,] 2 1 3
# 如果改成按行填充,将 byrow=TRUE就好
矩阵元素的替换
> x[,3] <- NA
> x
[,1] [,2] [,3]
[1,] 1 3 NA
[2,] 2 1 NA
> x[is.na(x)] <- 1 # 缺失值用1代替
> x
[,1] [,2] [,3]
[1,] 1 3 1
[2,] 2 1 1
矩阵统计运算
矩阵的排列是有方向性的,规定矩阵按列排列,一般不说明的时候,统计函数也是按列计算(但是可以用MARGIN来改变,等于1代表列,等于2代表行)
cov()与cor()分别计算矩阵的协方差矩阵和相关系数阵;
可以进行标准化scale(x, center=T, scale=T) ;
按列求均值apply(x, MARGIN=2, FUN=mean)
了解下R的数据框 Data frame
虽然说数据框与矩阵很相似,也是二维表格,也是要求各个变量的观测值长度相等,但是,在数据框中,行和列的意义是不一样的, 其中列表示变量,行为观测
提取
- 提取一列:
数据框名$变量名 - 提取满足条件子集:例如
subset(df, con1 == "treated" & con2 > 100)
添加
- 基本方法:
df$val1 <- condf是数据框,val1是新变量,con是定义的val1元素 - 使用with:
df$val1 <- with(df, con) - transform一次增加多个变量:
df <- transform(df, val1 = con, val2 = con2)
数据保存
一般用write.table()或者save()
保存为简单的文本文件:
write.table(df, file="/path/", row.names = F, quote = F)row.names =F 表示行名不写入文件;quote = F表示变量名不放在双引号中保存为逗号分隔(csv):用
write.csv()保存为R格式文件:
save(df, file="/path/")或者保存全部
save.image(),它等价于save(list =ls(all=TRUE), file=".RData")
数据读取
读取数据集
R内置的基本数据集有100多个(常为数据框和列表)。它们随R的启动全部一次性自动载入,通过命令data() 可以查看全部的数据集(也包含了通过library()加载的包中数据集);使用data(package = "pkname") 可以列出包pkname中的所有数据集,但是可能还未被加载,确定要用的时候可以加载包
读取Rdata
涉及多个数据集的分析时,最常使用load("/path/")
R的编程思维
控制结构中,条件语句少不了,例如
if (条件) 表达式1 else 表达式2,但是这样有些冗余,可以利用ifelse(条件, 表达式1, 表达式2)循环结构中,知道终止条件用for();不知道运行次数用while()
一般将一组命令放在大括号中=》模块化编程
# 一般格式:函数名 = function(变量列表) 函数体 # 例如一个画图函数 > myfun <- function(x, y) { data <- read.table(x) plot(data$V1, data$V2, type="l") title(y) }代码要增加注释,设置行前自动缩进
命令向量化(vectorization) ,就是将循环隐含在表达式中,例如条件语句可以用逻辑索引向量代替
for (i in 1:length(x)){ if (x[i] == b) x[i] <- 0 else y[i] <- 1 } # 这么长的函数,其实就是为了判断x中元素是否为b,等于b就赋值0;不等就赋值1 # 可以用下面代替 x[x == b] <- 0 x[x != b] <- 1向量化快的原因是:R中使用向量化会立即调用C语言,计算时比R快100倍
创建project来运行项目,这样一是可以方便读取存储;二是不同项目分类存放,方便查找更新
想要把脚本从头到尾运行一遍,用
source(),记得添加绝对路径