041-1个萝卜一个坑,1个基因n个名
刘小泽写于18.10.8
基因的研究越来越深入,如何从庞杂的数据中找到我们想要的基因是一项挑战,因为一个基因有多个名字
那些年我们关注的热点基因
自1960年以来,研究最火的可以说当属TP53基因,与它相关的文献数不胜数
它作为抑癌基因编码的p53蛋白是一种肿瘤抑制因子,可以说是基因组的守护者,它通过激活细胞周期停滞和细胞凋亡等几种防御机制来抑制肿瘤发生,另外p53还能帮助心脏病患者病后恢复(10.1038/nature13839)。当tp53突变或者p53蛋白发生失活时癌细胞能够存活(10.1038/nature19759),它的结构不太稳定,就有文章研究它怎么突变的(10.1038/srep32535)。另外p53可以保护端粒,促进DNA修复(10.15252/embj.201490880),它的同源蛋白Tap73却对肿瘤生长有促进作用(10.1038/ncb3130)。它这么重要,因此会成为众矢之的,有大概一般的肿瘤病例发现了TP53的突变。
另外还有:TNF:编码肿瘤坏死因子;EGFR 编码膜融合蛋白受体,一般的耐药性肿瘤中会发现它的突变;VEGFA 编码血管内皮生长因子,促进血管生长;APOE 编码载脂蛋白E,在胆固醇和脂蛋白代谢过程起作用;IL6编码白介素6,用于免疫系统;TGFB1 编码转化生长因子β1,调控细胞增殖分化;MTHFR 编码亚甲基四氢叶酸还原酶,用于氨基酸代谢;ESR1 编码雌性激素受体1,研究乳腺癌需要关注;AKT1 编码信号转导信号,将相邻的蛋白磷酸化用于激活蛋白分子;TNF 调控炎症反应,如治疗风湿性关节炎等炎症;RAS存在于90%的胰腺癌中,还存在于结肠癌、肺癌、黑色素瘤。
关键基因就是杠杆的支点,支点变化就会导致结果不同(健康或致病)
怎样判断是不是关键基因,主要看功能:促进细胞生长、分裂还是抑制细胞生长、增殖。大部分关键基因是信号通路蛋白,也就是各种各样的蛋白激酶;或者与代谢相关,另外还有与核酸结合的蛋白,作用是转录启动因子、稳定结构等。例如
ATM、AKT1、ABL1、APC、ALK、
BRCA1、BRCA2、BRAF
CDH1、CSF1R、CDKN2A、CTNNB1
EZH2、EGFR、ERBB2、ERBB4
FLT3、FGFR1、FGFR2、FGFR3、FBXW7
GNAS、GNA11、GNAQ
HER2、HNF1A、HRAS
IDH1
JAK2、JAK3
IDH2
KDR、KIT、KRAS
MPL、MET、MLH1
NPM1、NOTCH1、NRAS
PTEN、PIK3CA、PDGFRA、PTPN11
RB1、RET
SMO、SRC、SMAD4、SMARCB1、STK11
TP53
VHL
具体每个基因发挥的作用,可以去NCBI检索
如何看基因的检索结果
就拿乳腺癌抑制基因BRCA1来说吧,先说下背景知识
1990年,美国伯克利加利福尼亚大学发现首个乳腺癌遗传基因BRCA1,位于第17号染色体,一旦BRCA1发生突变而失去功能,其突变携带者的乳腺癌风险将增加50%~85%、卵巢癌风险增加15%~45%。总的来说,它很重要!
先在NCBI进行检索BRCA1:https://www.ncbi.nlm.nih.gov/gene/672

BRCA1又叫IRIS、BRCC1,又或者ENSG00000012048、OTTHUMG00000157426。我们一般使用基因的Official Symbol (这里的BRCA1)
第一行的信息
BRCA1 BRCA1, DNA repair associated [ Homo sapiens (human) ]可以得知这个基因和DNA修复有关,BRCA这四个字母来源其实也就是Breast Cancer,方括号中是物种第二行的信息
Gene ID672,表示这个基因在NCBI Entrez gene数据库中的代号什么是Entrez?
Entrez是一个综合性在线资源检索器,包含核酸、蛋白质、基因、基因组、GEO、pubMed等很多常用的数据库,把序列和相关文献都汇集到一起,用起来就像谷歌百度一样包罗万象。相信你不少听到别人说去NCBI 查一下,其实准确来说是去Entrez查一下,因为NCBI只是一个组织,Entrez才是干活的
什么是Entrez ID?
NCBI的Gene数据库包含了不同物种的基因信息,其中每一个基因都被编制一个唯一的识别号ID(因此不同生物或者同属不同种的生物间的同源基因编号也不相同), 这个ID就叫做Entrez ID,就是基因身份证啦。它对应于染色体上一个gene location
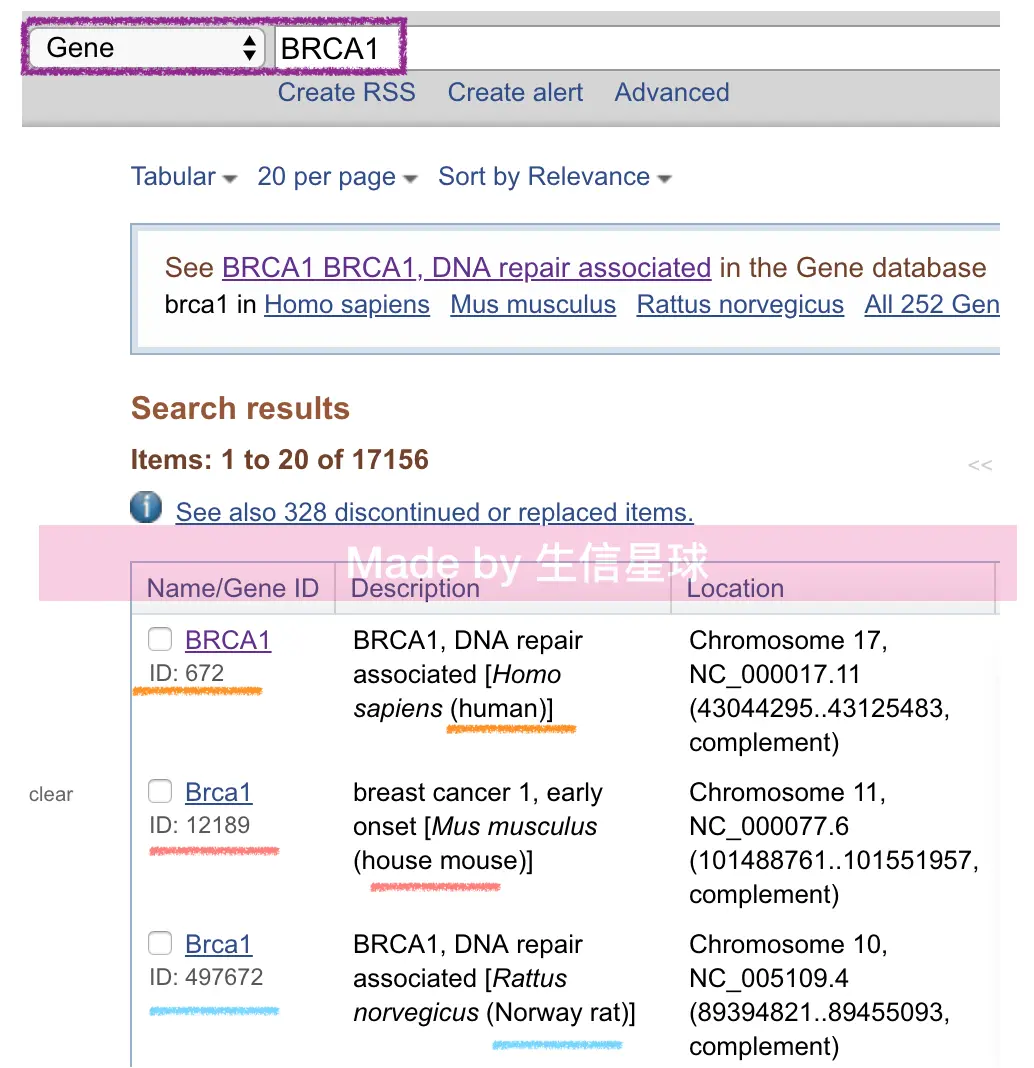
如何检索Entrez?
选择Gene数据库,然后输入基因名(symbol)或者编号(ID),比如上面检索BRCA1的过程就是这样
第三行
Official/Gene symbol这个是我们日常所说的基因名,也就是这里的BRCA1,这个名称是由HGNC提供的。HGNC是HUGO Gene Nomenclature Committee,HUGO是Human Genome Organisation即国际人类基因组织。当然仅限于人类的基因有provided by HGNC。并且不是所有的基因都有official symbol的,如果缺少HGNC提供的symbol,那么就在Entrez ID前加上LOC前缀,比如LOC109761693,前面的标题也变成了Gene Symbol因此,NCBI的基因都具有Entrez ID和symbol,但是不一定有官方的HGNC symbol
第四行
Official Full Name官方指定全称第五行
Primary source官方名称来源,会链接到HGNC网站关于BRCA1的介绍,在HGNC中的代号是HGNC:1100第六行
See related相关的其他数据库名称:Ensembl:ENSG00000012048很明显是Ensembl数据库中的ID号。Emsembl是英国Snager研究所和欧洲分子生物学实验室(EMBI-EBI)共同运作的一个数据库,目的是对真核生物的基因组进行自动化的注释,其中脊椎动物最多,包括爬行类、鸟类、鱼类、哺乳类和两栖类。 命名规则:ENSxxxG/T/E,xxx表示物种(除了人类不需要)。其中ENS表示Ensembl,最后的G表示基因ID;T表示转录本ID;E表示外显子ID需要注意的是有的基因名称后面有小数点,后面的数字代表版本,实际分析的时候需要去掉
MIM:113705这个是OMIM数据库中的代号,OMIM是0nline Mendelian Inheritance in Man即在线版的人类孟德尔遗传,提供人类基因和遗传紊乱的数据,专注于遗传病。其中会对这个基因进行详细的描述,并且有相关的参考文献作指导Vega:OTTHUMG00000157426来自Vega数据库Vertebrate Genome Annotation即脊椎动物基因组注释
一个基因几个名呢?
大部分基因都有自己的5种类型ID,特定的基因如miRNA在miRBase中有自己的ID;LncRNA虽然没有标准的命名,但是相关的数据库IncRNAdb、LNCipedia都有自己的一套命名方式
5种类型:NCBI的entrez ID及gene symbol,Ensembl的gene ID,UCSC的gene ID,KEGG的gene ID,大部分的ID都可以在HGNC中查找
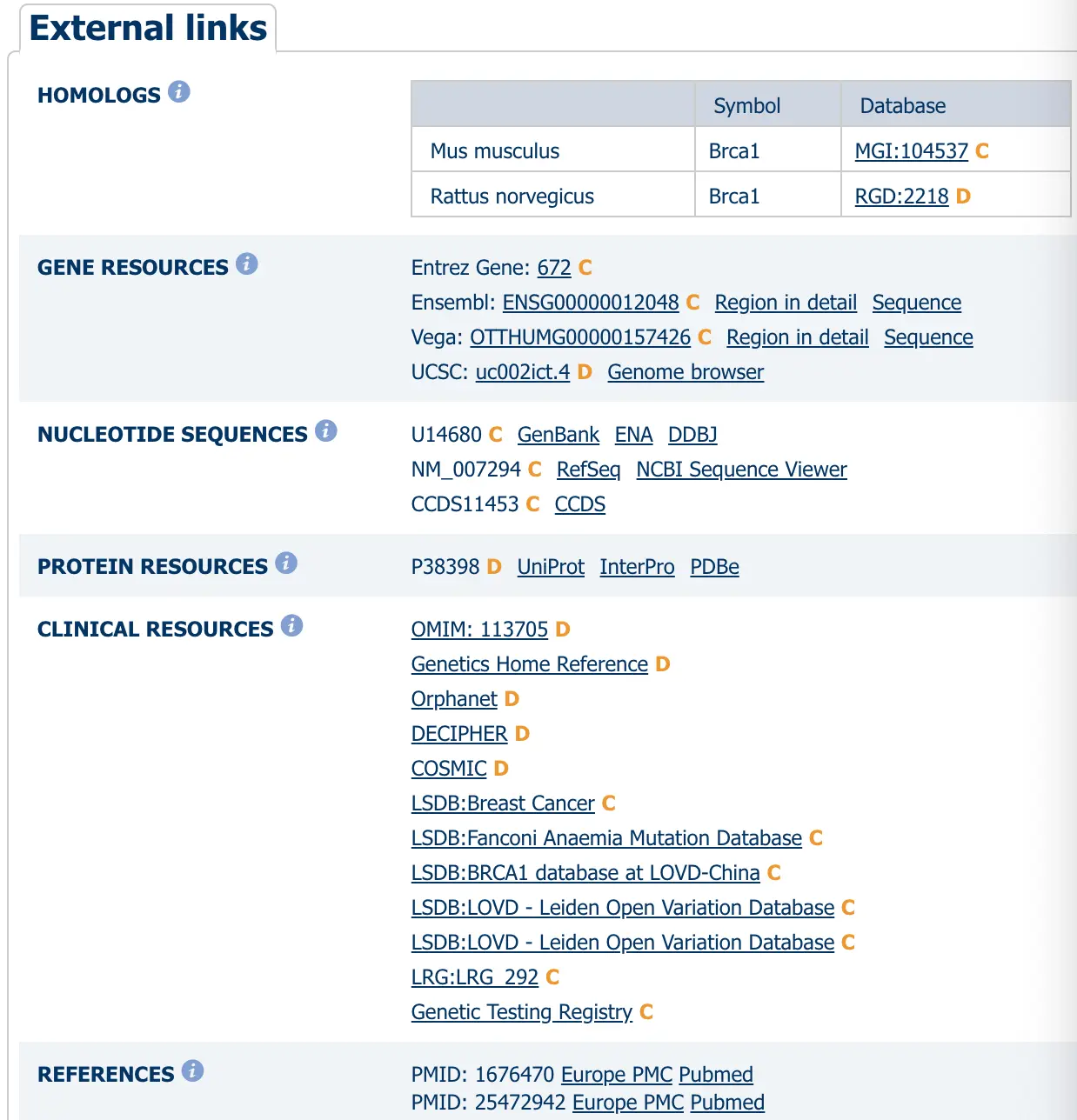
前三种上面👆有所了解了,那么UCSC的ID以uc开头,BRCA1对应的就是uc002ict.4 ;
KEGG的gene数据库的命名方式是:三个小写字母表示物种,后面再加ID号,例如BRCA1对应hsa:672 https://www.kegg.jp/dbget-bin/www_bget?hsa:672
基因ID转换
常常在Entrez gene ID与Ensembl gene ID以及gene ID与gene symbol之间转换 ,
常用的工具就是clusterProfiler
使用方法:bitr(geneID, fromType, toType, OrgDb, drop = TRUE)
geneID是输入的基因ID,fromType是输入的ID类型,toType是输出的ID类型,OrgDb注释的db文件,drop表示是否剔除NA数据