031-R数据科学之日常积累
刘小泽开始写于18.9.4晚,这必定是一个持续性更新的过程 昨天jimmy一发朋友圈,单篇阅读量很快超过了我们的关注人数😂开心之余,今晚拿起了数据科学这本书看了起来~
正如书的安排,将第一部分分给了可视化,确实让人耳目一新,学习R可视化并且用最好用的ggplot2工具,让学习变成一种享受。 我会按学习的内容梳理重点问题
前言
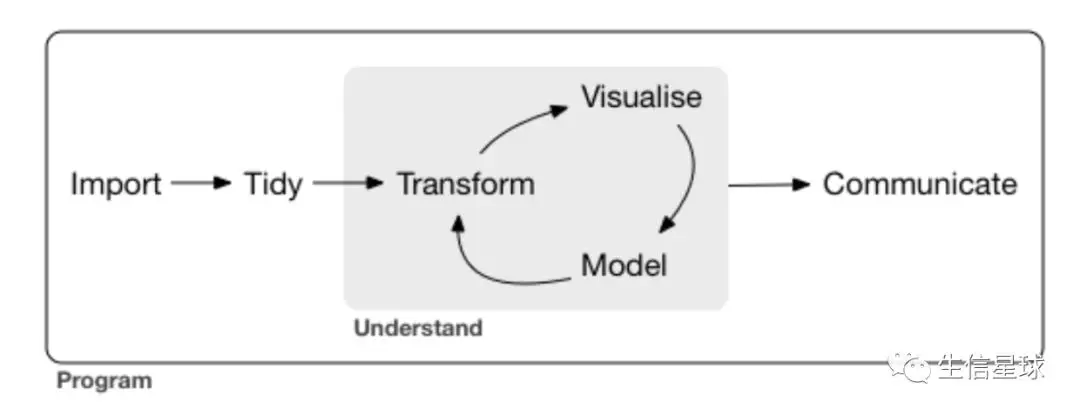
需要整洁的数据tidy data
每一列是一个变量,每一行是一个观测
需要安装tidyverse包
包括了ggplot2/tibble/readr/purrr/dplyr,使用tidyverse_update()检查更新
指定对象
包的名称后用两个冒号,如dplyr::mutate()
ggplot绘图
绘图模版
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPING>))
这个思路很棒!也讲出了ggplot的作图逻辑
- 无论什么图,首先需要输入的就是数据集
<DATA>,这时绘制的是一张白纸; - 接下来就看你需要做什么图了,就是选择几何对象的过程,比如要做散点图,就将
<GEOM_FUNCTION>替换成geom_point; - 有了几何对象,接下来就要考虑,我们数据集中的数据怎么映射上去呢,x轴代表什么,y轴又代表什么呢?这个就是
<MAPPING>需要做的事情——指定映射变量; - 指定完变量后,就要想,怎么设置字体大小(size),形状(shape)、【填充|边框】颜色(fill | color)、透明度(alpha)等等,这些叫图形属性,也都是在
<GEOM_FUNCTION>中完成; - 绘制完一个图层后,当然可以继续新加图层,覆盖到原来之上(比如这里的散点图)
绘图注意
不要将无序变量映射为有序图形属性,什么样的变量就用什么样的属性
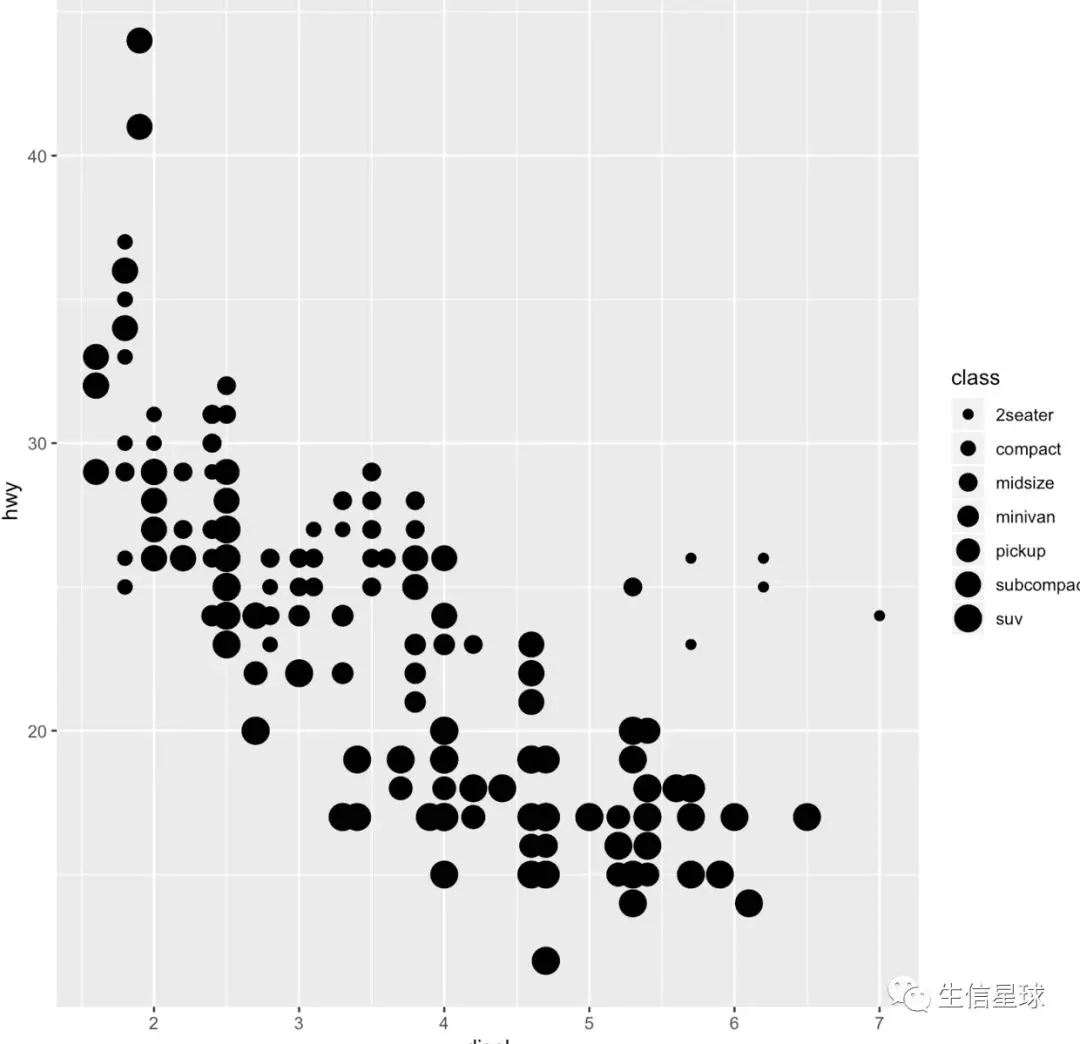
有序图形属性包括:size;无序属性包括:shape、size 进行图形属性设置时,有的属性是有序的图形属性,比如size,就是它是和数据的大小顺序有关的,反映出来的结果应该是:数值越大,点的大小越大。 但是如果用一个无序的变量(比如mpg数据集中的class变量,它只是一个分类的作用)去映射size,结果就会根据不同类别的class表现大小,基本上结果是看不出来什么问题的
ggplot(data = mpg)+ geom_point(mapping = aes(x = displ, y = hwy, size= class))
ggplot2最多同时使用6种形状
绘图模版的倒数第二条中,设置颜色用字符串,设置大小用毫米,设置形状用数值。关于形状:
空心-边界颜色-color 【0-14】 实心-填充颜色-color;【15-20】 填充-边界颜色-color,填充颜色-fill【21-24】
一行代码写不完,可以用+然后换行,但是+必须在结尾
图形分面:特别适合添加分类变量 单个变量:
facet_wrap(~变量,nrow=)两个变量:facet_grid(变量1~变量2)ggplot中有大于30种几何对象,就是做出来的图形,但是对于不用的图进行设置的属性也有些差别,比如:带线的图就不能用点图的shape设置形状,可以用linetype设置实线、虚线等
show.legend=T/F设置是否显示图例创建表格可以用
demo <- tribble( ~a, ~b, "bar_1", 20, "bar_2", 30, "bar_3", 40)在<GEOM_FUNCTION>()中还可以添加统计变换
#stat_summary:汇总统计,主要计算数据集合的最大值、最小值、平均数等; #stat_bin:封箱统计,将数据划分成一个个的区域,然后在外面嵌套汇总统计; #stat_smooth:线性回归、非线性回归以及各种平滑插值算法,用于查找数据的规律; #stat_density:样本估计总体的概率密度;位置调整position
#选项1.identity ggplot(diamonds,aes(x=cut, fill = clarity))+ geom_bar(position = "identity", alpha = 1/4) #设置透明度 ggplot(diamonds,aes(x=cut, color = clarity))+ geom_bar(position = "identity", fill=NA) #选择不填充,也就是完全透明,只有边框 #选项2.fill(和堆叠相似,但各组高度相同)方便比较比例 ggplot(diamonds, aes(x=cut, fill =clarity))+ geom_bar(position = "fill") #选项3.dodge(各组条形并列放置)方便比较数值 ggplot(diamonds, aes(x=cut, fill = clarity))+ geom_bar(position = "dodge", alpha=1/2) #选项4.适合散点图的jitter(随机抖动)避免因数据四舍五入而使部分值重叠 #不加抖动是这样 ggplot(mpg)+geom_point(aes(x= displ, y = hwy)) #加了是这样,可以看出数据聚集模式 ggplot(mpg)+geom_point(aes(x= displ, y = hwy), position = "jitter") #快速实现用geom_jitter ggplot(mpg)+geom_jitter(aes(x= displ, y = hwy))作出一条参考线:对角线
geom_abline();水平geom_hline; 竖直geom_vline
基础工作流
赋值
虽然=也可以,还是推荐使用<- 。因为=后来可能会引起混淆
快速输入<-,用Alt +减号
对象名称
小写字母,_分隔
调取快捷键帮助
alt + shift + K
学习dplyr
五大金刚: filter()按值筛选观测值;arrange()行重排序;select()按名称选取变量;mutate()使用现有变量创建新变量;summarize()获得摘要 【工作方式:函数(数据框,变量名称+操作) = 》结果返回新数据框】
一种设定:group_by(),可以改变上述函数的作用范围
#先加载参考数据集——航班概况
install.packages("nycflights13")
library(nycflights13)
filter
想同时输出结果并保存在一个变量中,可以这样:
(dec25 <- filter(flights, month == 1, day == 1))
比较数值—浮点数较特殊
> sqrt(2)^2 == 2
[1] FALSE
#计算机使用有限位数运算,因此sqrt(2)^2结果是个近似值,要采用near函数来判断
> near(sqrt(2)^2, 2)
[1] TRUE
逻辑运算
#找到11月或者12月的航班
filter(flights, month == 11| month == 12)
#但是,如果这样写:
filter(flights, month == 11| 12) #结果大不同
# 因为程序先看的是11 | 12,返回逻辑值是TRUE, 而TRUE代表数字1,因此结果就是相当于 filter(flights, month == 1),会找到1月份的航班
NA == NA => NA
NA是什么?=》not available的缺失值
打眼看去,很奇怪的表达,判断NA == NA,怎么结果还是NA? 按现实情况去解释就好理解了:豆豆的年龄未知(dou <- NA),花花的年龄也未知 (hua <- NA),那么豆豆花花的年龄一样吗(dou == hua?),不知道啊,所以还是NA
当然,要判断NA值,用is.na()
filter()默认只保留TRUE的行,排除FALSE、NA,如果要保留NA,例如
filter(df, is.na(x) |x>1 )
简写 %in%
选出x是y中的一个值的所有行
filter(flights, month %in% c(11,12)) #就是上面的简写
简化筛选条件
#如果要找出发或者到达延误时间小于2小时的航班【两种方法】
filter(flights, !(arr_delay >120 | dep_delay > 120))
filter(flights, arr_delay <= 120, dep_delay <=120)
另一个简单的选取数据函数between()
可以用于选取数据范围between(x, left, right)
参数left,right表示数据左边和右边范围,返回结果是逻辑值