231-学习动态网页爬虫RSelenium
刘小泽写于2021.1.26 今天摸索了半天,边学边实践,终于实现了自动化搜索
为什么要学这个?
继上次我探索了一个静态网站的api使用后【看: 懒惰迫使我学了点API的知识】,越发感觉爬虫的魅力所在,可以帮助我们节省不少时间,而且准确性还比人工高。
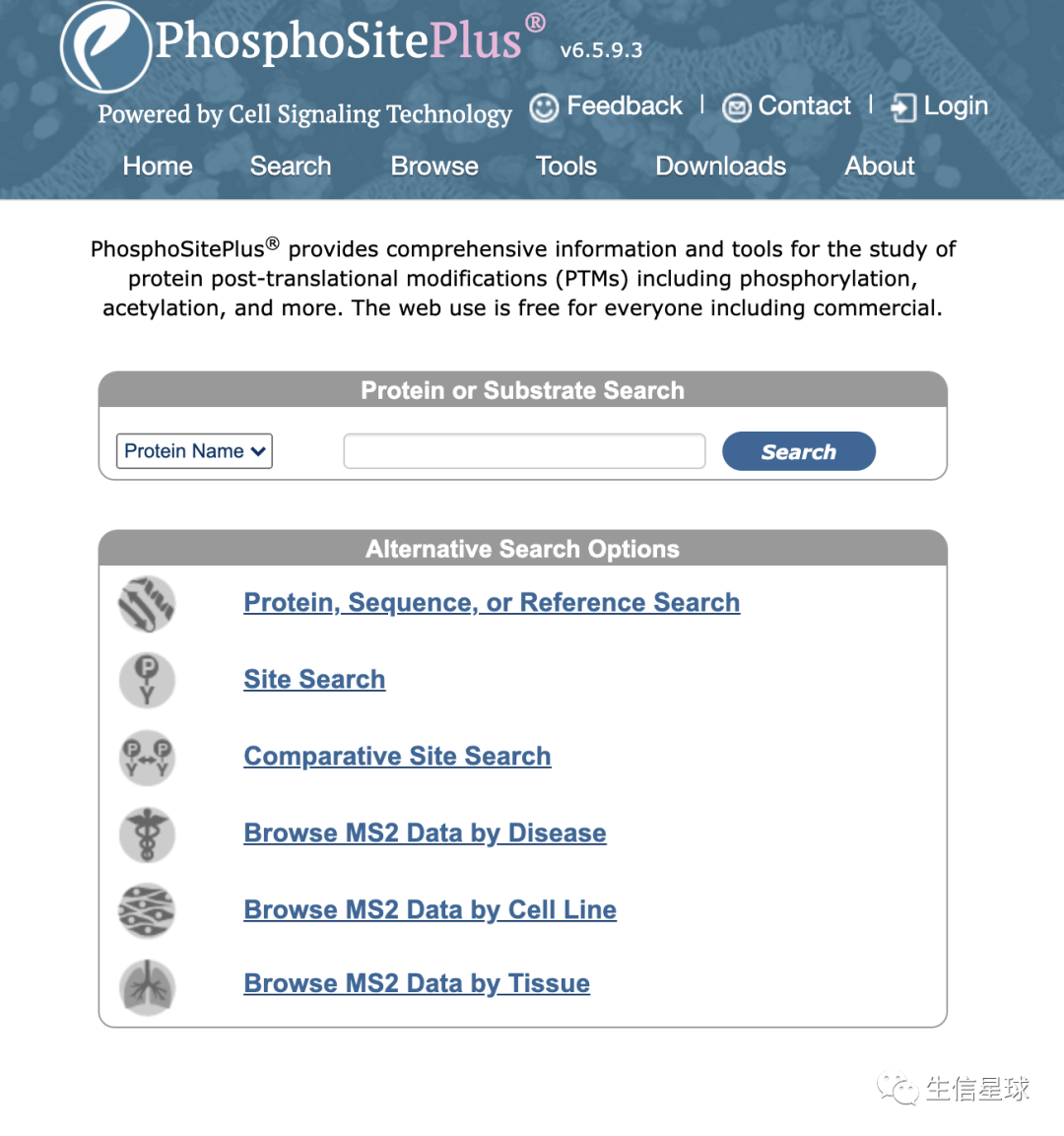
这次,又碰到一个任务,就是从phosphosite网站上查询一个蛋白的信息,并且比较人和小鼠的位点。网站是:https://www.phosphosite.org/homeAction,长这样:
为什么不能用上次的那个方法?
其实一开始我是想用来着,首先看网站没有提供数据下载,另外也没有api接口。更重要的是,当你去搜索时就会发现,你不停的点击点击,但是链接却不会更换。这也就是动态网页的一个特点。
那么对于这类网站怎么处理呢?
让代码来代替我的手
Selenium是一个 Web 端的自动化测试工具,直接运行在浏览器中,用来模拟用户操作。它不仅仅可以用作自动化测试,还有很多种玩法,比如 Python 的爬虫,实现某商品的秒杀,甚至是页游外挂脚本,只要是基于浏览器操作,只有你想不到,没有 Selenium 做不到,就是这么强大!
并且Selenium 支持的浏览器很多,比如Firefox、Chrome、IE、Opera 等等。
在R语言中,也开发出了一个叫做RSelenium的包,方便我们去调用,但是安装的准备工作相对较多
首先来安装
需要有java,打开terminal终端,运行
java --version,就知道有没有安装好java了下载selenium:https://selenium-release.storage.googleapis.com/3.141/selenium-server-standalone-3.141.59.jar
推荐使用chrome+ChromeDriver。需要注意的是:ChromeDriver要严格按照chrome的版本信息来下载,比如我的chrome是88.0.4324.96版本,就需要到ChromeDriver的官网(https://chromedriver.chromium.org/downloads)下载:https://chromedriver.storage.googleapis.com/88.0.4324.96/chromedriver_mac64.zip。另外还提供了mac 的M1芯片版本、linux版本、win32版本
友情提示:先不看这句代码的意思。假如你后期运行类似的命令,提示了这样的报错,就要先检查一下你的chrome与ChromeDriver版本是否适配

正确的操作都是下面👇这样的,中间没有任何提示
最后就是安装包了:
install.packages('RSelenium')
加载测试
首先打开terminal,运行下面的代码
# 如果下载到了~/Downloads,可以这么调用。-port可以自行指定,但要保证和下面的R代码一致
java -jar ~/Downloads/selenium-server-standalone-3.141.59.jar -port 4446
或者在R中
system("java -jar \"selenium-server-standalone-3.141.59.jar\" ",wait = FALSE)
但不管用什么方式打开,都要保证这个要后台运行,中间不要关闭
然后连接
library(XML)
library(stringr)
library(rvest)
library(RSelenium)
library(dplyr)
#连接Server
remDr <- remoteDriver(remoteServerAddr = "localhost"
, port = 4446 #这个port与上面保持一致
, browserName = "chrome")
# 这时就可以用 RSelenium 打开浏览器
remDr$open(silent = T)
此时你会看到一个空的浏览器窗口,并且显示“被控制”
这个工具的一些基础操作
能打开以后,就可以进行一些基础摸索了
比如打开一个网页
url <- "https://www.phosphosite.org/homeAction"
remDr$navigate(url)
就会看到浏览器自己会跳转到这个网站
除此以外,我们常用的浏览器操作都能实现,比如
# 回到上一頁
remDr$goBack()
# 前往下一頁
remDr$goForward()
# 取的目前網頁的網址
remDr$getCurrentUrl()
# 刷新
remDr$refresh()
# 查询远程服务器的状态
remDr$getStatus()
# 直接退出
remDr$quit()
# 用于关闭当前会话,也可以用作关闭浏览器
remDr$close()
难点在于如何获取想要的内容
推荐一个帮助获取CSS (Cascading Style Sheets )的chrome插件
SelectorGadget:https://selectorgadget.com/ 可以帮你快速定位 可以参考这一篇来学习如何使用:https://medium.com/datainpoint/r-essentials-web-scraping-8d0222c1e8d5
首先我想定位到搜索框
代码实现就是:
webElem <- remDr$findElement(using = 'css', value = "#searchString")
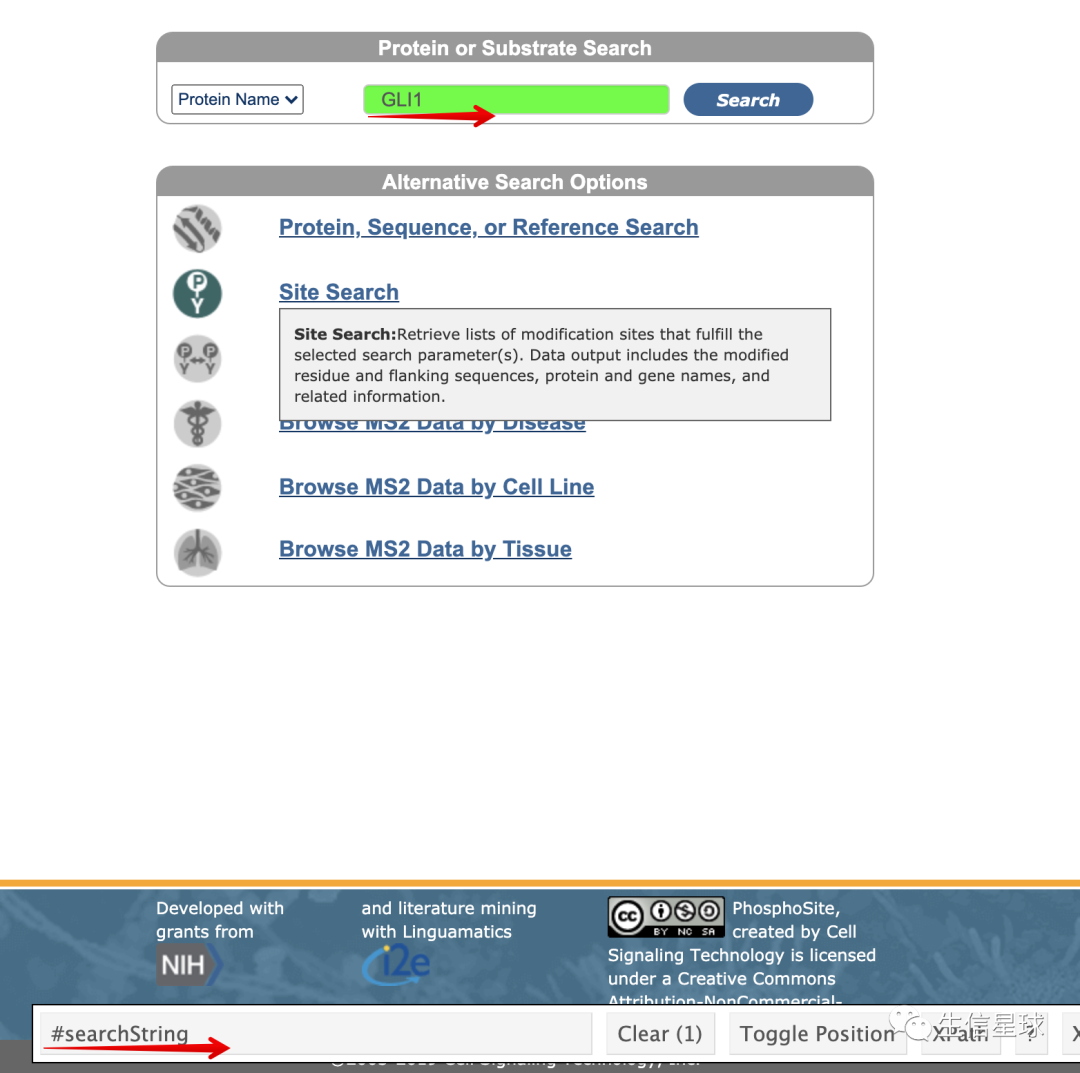
然后定位search按钮
remDr$mouseMoveToLocation(webElement = webElem)
remDr$click()
# 在文本框内输入要搜索的内容,并执行enter操作
webElem$sendKeysToElement(list('GLI1',key="enter"))
然后找到site table
webElem <- remDr$findElement(using = 'css', value = "#ui-id-3")
remDr$mouseMoveToLocation(webElement = webElem)
remDr$click()
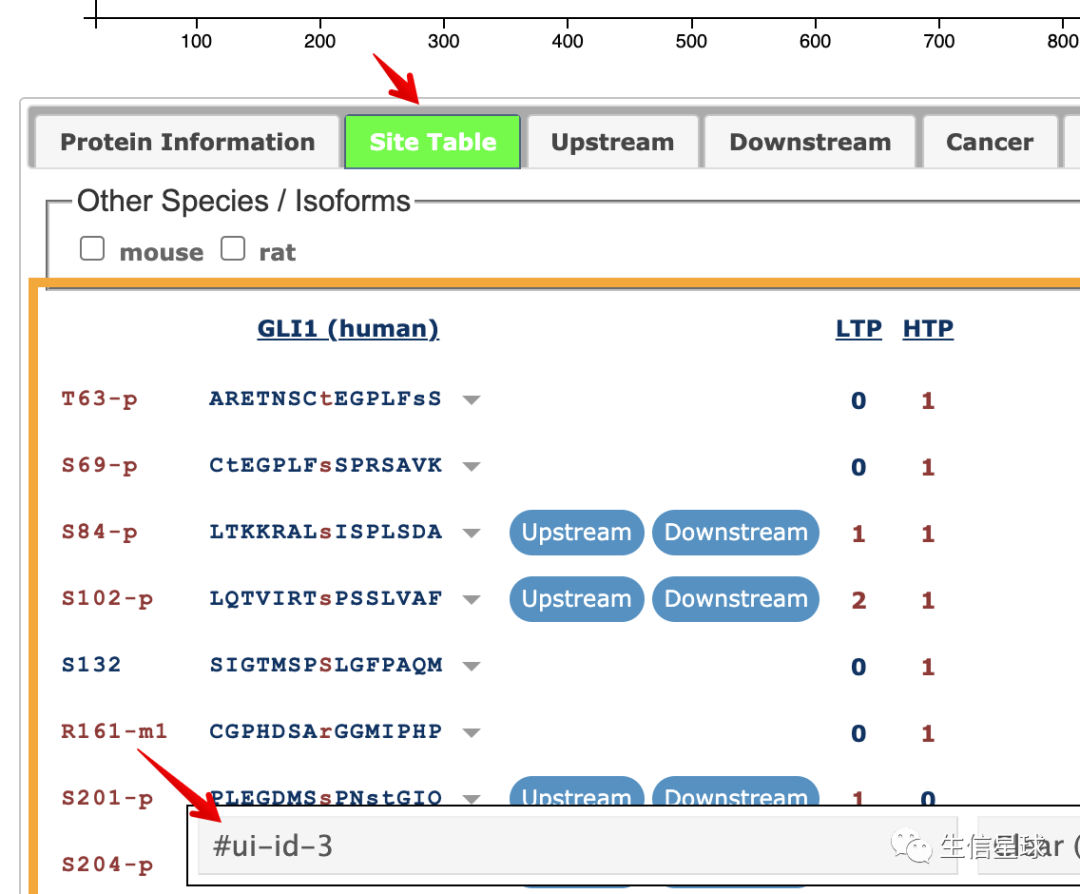
因为我们想同时看到human和mouse的信息,所以需要再找到mouse
同样的方法,定位到mouse的CSS为value-1
webElem <- remDr$findElement(using = 'css', value = "#value-1")
remDr$mouseMoveToLocation(webElement = webElem)
remDr$click()
得到以上我们想要的定位以后,我们可以去获取内容了
获取当前搜索结果的网站源码
page <- remDr$getPageSource()[[1]]
pg=readHTMLTable(page)
> class(pg)
[1] "list"
all=pg$siteTable_human
View(all)
看下其中存储的信息,是不是包含了我们需要的human和mouse信息?
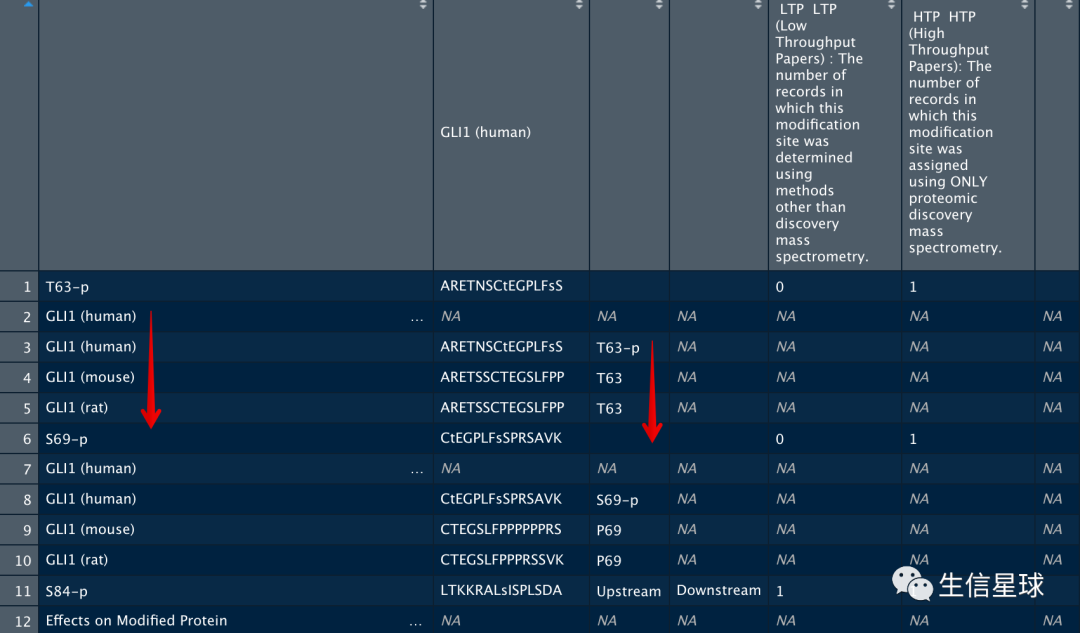
最后,就是简单的数据框提取啦
切换了另一个基因ID进行测试
下面的图A是网站的结果,图B的是我自己生成的,完美匹配!

再优化一点
循环配函数,真是香!
我把搜索id的爬虫代码写成一个函数,并且简化了其中一些不必要选项。这样在批量运行时更能清晰并且省时省力
看我鼠标一直没动哦!

最后
需要注意一点:一般为了避免反爬,在每次click操作之后,最好设置休息时间,比如:
remDr$mouseMoveToLocation(webElement = webElem)
remDr$click()
Sys.sleep(2)