154-如何将几万个Gene ID利用biomaRt转换
刘小泽写于19.12.11 先附上biomaRt使用说明:https://www.bioconductor.org/packages/devel/bioc/vignettes/biomaRt/inst/doc/biomaRt.html
问题:什么时候要用biomaRt转换?
【可以看一下: ID转换失败,爬起来继续high】
其实用biomaRt的优点是:转换结果很丰富,可以用来应急(当根据 org.xxx.db 进行转换时,得不到想要的结果时,就可以考虑用一下它)。当然也不是说它的转换就是最完美的,也存在很多匹配不上的基因,但这部分的数量要少一些。差异的背后其实就是数据库的不同
biomaRt的转换需要和Ensembl的数据库进行交互,带来的一个问题就是比较慢。如果真的有实际应用biomaRt的需求,但苦于转换的速度,那么怎么比较好地解决这个问题呢?
例如
现在有4万个基因,如果使用bitr或者mapIds,一次给到给函数,没有问题,转换速度很快。
但是如果一次性给到biomaRt ,可能成功,可能失败,取决于网络。
失败的表现就是:迟迟不出结果,直到…

或者其他的提示:(大体意思是)时间到了,我运行不完了。因为它默认只能运行3分钟
方案一 如果想一次性运行完大量基因
这个方法首先可以尝试,不行的话再换第二种
执行起来也很简单,就是给函数改一个参数: useCache = F
library("biomaRt")
value <- x
attr <- c("ensembl_gene_id","hgnc_symbol")
ensembl <- useMart("ensembl", dataset = "hsapiens_gene_ensembl")
ids <- getBM(attributes = attr,
filters = "ensembl_gene_id",
values = value,
mart = ensembl,
useCache = F)
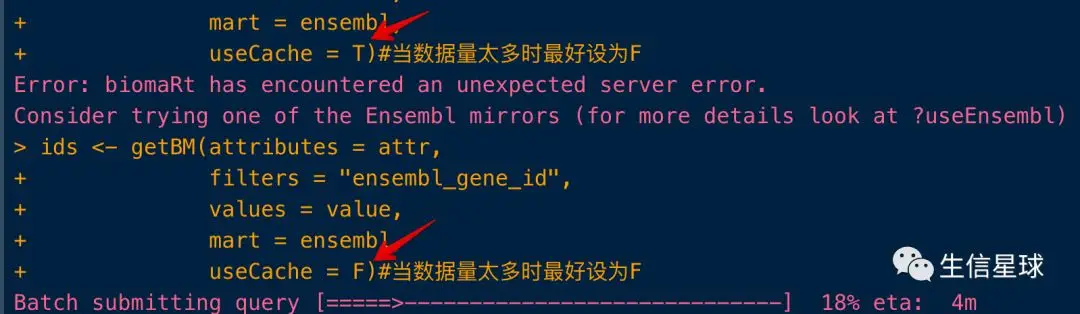
**如果使用useCache = F第一次失败了,可以再改成useCache = T,**然后就会有一个断点续传的操作(别问我怎么知道的)
方案二 如果想一次性运行总是报错,可以尝试拆分运行
可以把几万个基因分成小块(chunk,熟悉STAR的朋友对这个名称肯定不陌生)
比如将每个小块的基因数设成50个(这样可以保证每个小块运行不会断掉)
# 例如x是所有的4万个基因ID
length(x)
n=floor(length(x)/50)
name_list=list()
chunk <- function(x,n) split(x, factor(sort(rank(x)%%n)))
name_list <- chunk(x,n)
length(name_list) # 最后得到的chunk列表是 40000/50 = 800个
之后进行一个循环操作,并将循环将结果加入空的数据框
trans_id = data.frame(ensembl_gene_id=character(),
hgnc_symbol=character())
library("biomaRt")
ensembl <- useMart("ensembl", dataset = "hsapiens_gene_ensembl")
for (i in 1:length(name_list)) {
value <- name_list[[i]]
#print(value)
attr <- c("ensembl_gene_id","hgnc_symbol")
ids <- getBM(attributes = attr,
filters = "ensembl_gene_id",
values = value,
mart = ensembl,
useCache = F, #当数据量太多时最好设为F
curl = 'CURLHandle')
}
这个运行的时间可能会比较久
拿到结果后别忘了检查一下
sum(is.na(ids$hgnc_symbol)) # 看下有没有NA(一般是不会的,即使没有对应上,也会返回空字符串"")
> sum(ids$hgnc_symbol == "") # 看看有多少没有对应上的
[1] 13438
# 如果没有对应上,就在hgnc_symbol那里依然填上Ensembl ID
if (sum(ids$hgnc_symbol == "") != 0) {
ids$hgnc_symbol[ids$hgnc_symbol == ""] <- ids$ensembl_gene_id[ids$hgnc_symbol == ""]
}
# 再次检查
> sum(ids$hgnc_symbol == "")
[1] 0
# 最后的结果
> head(ids)
ensembl_gene_id hgnc_symbol
1 ENSG00000000003 TSPAN6
2 ENSG00000000005 TNMD
3 ENSG00000000419 DPM1
4 ENSG00000000457 SCYL3
5 ENSG00000000460 C1orf112
6 ENSG00000000938 FGR