110-AWK是门大学问(上)
刘小泽写于19.4.29 在grep、sed、awk中awk应该是最为强大的了,它可以单独作为一门语言去学,但是现在没有必要,掌握基础的用法就可以啦。 我认为,awk的作用简而言之就是以行输入,以列处理 本次内容来自一本叫做"sed-awk-101Hacks”,可以利用一些简单的小例子来练习,虽然和生物无关,但是技术到位了日后才可以顺利分析
首先在linux中新建几个文件,作为示例数据
第一个文件:有三列,分别是员工号、姓名、职位
cat >employee.txt
101,John Doe,CEO
102,Jason Smith,IT Manager
103,Raj Reddy,Sysadmin
104,Anand Ram,Developer
105,Jane Miller,Sales Manager
AWK的基本语法
Basic
awk -Fs '/pattern/ {action}' input-file
- -F表示分隔符(filed delimiter)
- /pattern/和{action}应该放在一个单引号中
- /pattern/指的是匹配。当然这一项是可选的,如果不提供的话,awk默认对输入文件的所有行进行遍历;如果指定了,awk只会对匹配上的进行操作
- {action}中是awk的精髓,可以包含一个或多个命令
比如:
awk -F: '/mail/ {print $1}' /etc/passwd
mail
-F指定:是分隔符(可以先看下/etc/passwd这个文件;awk默认是空格分隔)。然后匹配上mail的输出第一列
将命令封装到单独脚本中
如果要利用awk执行许多命令,可以将一系列的/pattern/ {action} 保存到比如叫test.awk的脚本中,然后调用
awk -F -f myscript.awk input-file
这个脚本文件后缀可有可无,有后缀只是为了让后期修改更容易识别[这里要说明一下,linux中后缀的概念并不是那么重要,起到的作用一般是标识]
当然,如果自己在脚本中指定了分隔符,那么直接调用脚本就好
awk -f myscript.awk input-file
awk编程结构(BEGIN,body,END)
- BEGIN:就是
BEGIN {commands}只在开头,也就是awk开始执行真正的命令前; 它是打印header行、初始化变量的好帮手; BEGIN中可以包含一个或者多个awk命令; BEGIN必须要大写; BEGIN部分可有可无 - Body:就是
/pattern/ {action}每读入一行就执行一次这个命令; - END:就是
END {commands}
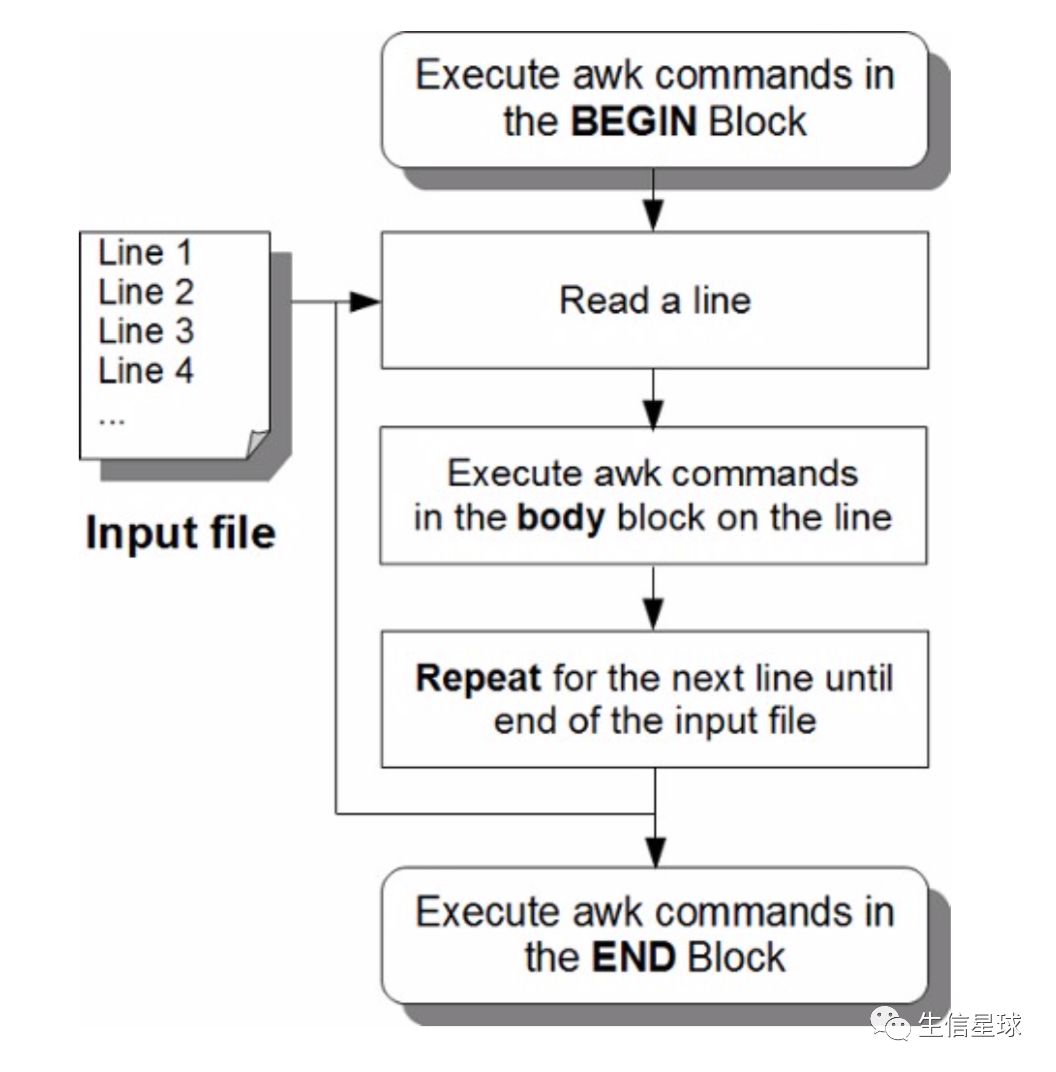
举个例子:
awk 'BEGIN { FS=":";print "---header---" } /mail/ {print $1} END { print "---footer---"}' /etc/passwd
---header---
mail
---footer---
可以看到,在BEGIN中也是可以指定分隔符的,它用的是FS=":"
如果不想把上面这么长的命令写在一行中,也可以这样:
cat >test.awk
BEGIN {
FS=":"
print "---header---"
}
/mail/ {
print $1
} END {
print "---footer---"
}
awk -f test.awk /etc/passwd
几种常见的awk表现形式:
只有body
awk -F: '{ print $1 }' /etc/passwd全套
awk -F: 'BEGIN { printf "username\n------\n"} \ { print $1 } \ END { print "------" }' /etc/passwdbody加BEGIN/END其中一个
awk -F: 'BEGIN { print "UID"} { print $3 }' /etc/passwd只用BEGIN或者END
结果和echo输出的效果一样,例如
awk 'BEGIN { print "Hello World!" }' Hello World!
当指定多个文件时
比如对两个文件进行awk操作,它是先对第一个文件的所有行操作完,再进行第二个文件操作,但是BEGIN和END只输出一次
awk 'BEGIN { FS=":";print "---header---" } \ /mail/ {print $1} \
END { print "---footer---"}' /etc/passwd /etc/group
Print命令
默认情况下,awk的print函数打印所有的行,比如
awk '{print}' employee.txt
101,John Doe,CEO
102,Jason Smith,IT Manager
103,Raj Reddy,Sysadmin
104,Anand Ram,Developer
105,Jane Miller,Sales Manager
它和{print $0}的效果一样,因为$0是每一行中全部记录的意思
要是指定输出某一列,就用$加数字,指定提取第几列,比如
awk '{print $2}' employee.txt
Doe,CEO
Smith,IT
Reddy,Sysadmin
Ram,Developer
Miller,Sales
但是,发现和想要的不对!为什么?
因为分隔符的问题,awk默认是空格,但是这里是逗号分隔,因此加一个-F就好了
awk -F ',' '{print $2}' employee.txt
John Doe
Jason Smith
Raj Reddy
Anand Ram
Jane Miller
当分隔符只有一个字符时,指定形式很随意,可以双引号,可以单引号,还恶意没有引号
awk -F ',' '{print $2}' employee.txt
awk -F "," '{print $2}' employee.txt
awk -F, '{print $2}' employee.txt
格式匹配 pattern matching
比方输出包含manager的姓名和职位
awk -F ',' '/Manager/ {print $2, $3}' employee.txt
Jason Smith IT Manager
Jane Miller Sales Manager
打印员工号是102的姓名
awk -F ',' '/^102/ {print "Emp id 102 is", $2}' \ employee.txt
Emp id 102 is Jason Smith
刘小泽写于19.4.30 继续探索AWK
内置变量
FS-Field Separator
默认的分隔符是空格(但是数量不限,于是tab分割也包含在内),如果要自己制定,可以用-F,例如
awk -F ',' '{print $2, $3}' employee.txt
利用内置的变量FS也可以实现,需要在BEGIN{}中实现,比如
awk 'BEGIN {FS=","} {print $2, $3}' employee.txt
但是,使用-F更加灵活,可以使用单引号、双引号或者不用引号;使用FS就必要用双引号
在BEGIN或者END中可以使用多个命令,比如在开头指定分隔符,并且打印标题
需要注意的是,BEGIN或END中多个命令之间用分号分隔
awk 'BEGIN { FS=","; \
print "-------------\nName\tTitle\n-------------" } \
{ print $2,"\t",$3; } \
END {print "-------------"}' employee.txt
下面再新建一个文件,其中包含多种分隔符, : %
cat >employee-multiple-fs.txt
101,John Doe:CEO%10000
102,Jason Smith:IT Manager%5000
103,Raj Reddy:Sysadmin%4500
104,Anand Ram:Developer%4500
105,Jane Miller:Sales Manager%3000
遇到这种文件也不用担心,只需要利用正则表达式来指定多个FS,比如FS = "[,:%]" 表示分隔符可以是逗号、分号或者百分号,因此,如果要打印第2、3列的姓名和职位,就可以
awk 'BEGIN {FS="[,:%]"} {print $2, $3}' \ employee-multiple-fs.txt
John Doe CEO
Jason Smith IT Manager
Raj Reddy Sysadmin
Anand Ram Developer
Jane Miller Sales Manager
OFS-Output Field Separator
上面说的FS是输入分隔符,OFS就是输出指定分隔符。默认也是利用空格分隔。上面👆例子中,默认是空格分隔的。如果要将输出的分隔符指定为分号,可以用
awk 'BEGIN {FS="[,:%]"} {print $2,":",$3}' employee-multiple-fs.txt
John Doe : CEO
Jason Smith : IT Manager
Raj Reddy : Sysadmin
Anand Ram : Developer
Jane Miller : Sales Manager
这是一种方式,但更多用的是OFS变量
需要注意的是,OFS指定的分隔符前后不要有空格
awk 'BEGIN {FS="[,:%]"; OFS=":"} {print $2,$3}' employee-multiple-fs.txt
# 也是一样效果
另外,注意在print函数后面的参数之间使用逗号分隔的话,那么输出结果就是按空格分隔;如果参数之间什么也不写,只是罗列上,那么输出结果就是连在一起,比如:
解释:如果awk的print中出现了逗号分隔,那么awk就会调用默认的OFS,也就是输出结果用空格
awk 'BEGIN { print "test1","test2" }'
test1 test2
awk 'BEGIN { print "test1" "test2" }'
test1test2
RS-Record Separator
之前见过FS是列分隔符(只要见到这个符号,就分一列出来),这个RS就相当于行分隔符(见到这个符号就换一行)。
先举个简单的例子:
# 这个文件是一行的,都是”员工id,姓名“这样的形式
cat >employee-one-line.txt
101,John Doe:102,Jason Smith:103,Raj Reddy:104,Anand
Ram:105,Jane Miller
其中101,John Doe 是一个小字段,它和其他的字段用冒号分隔。现在如果想提取出每一个姓名,直接使用下面这个命令会是怎样?
awk -F, '{print $2}' employee-one-line.txt
结果会输出John Doe:102 ,而不是想要的John Doe ,这个原因就是:我们的文件是一行,而且有两种分隔符
看到多个分隔符的情况,首先想到的就是之前介绍的
BEGIN {FS="[,:]"},但是这样做的结果是把之前文本分的更细,如果要提取所有的姓名,那么就要print所有偶数列。于是有点麻烦
这里用到一个RS的东西,它和FS搭配使用:首先RS指定为冒号,将一整行的文本分成5行小字段,接着利用FS指定为逗号,在每个小字段中提取出第二列
awk -F, 'BEGIN { RS=":" } \
{ print $2 }' employee-one-line.txt
John Doe
Jason Smith
Raj Reddy
Anand Ram
Jane Miller
那么来一个进阶的:
现在有这样一个文件:
cat >employee-change-fs-ofs.txt
101
John Doe
CEO
-
102
Jason Smith
IT Manager
-
103
Raj Reddy
Sysadmin
可以看到,这里的列分隔符FS是换行符\n,行分隔符RS是- 再加一个换行符,因此如果要变成熟悉的样子,只需要在BEGIN中指定各种分隔符
awk 'BEGIN { FS="\n"; RS="-\n"; OFS=":" } {print $2, $3}' employee-change-fs-ofs.txt
John Doe:CEO
102:Jason Smith
103:Raj Reddy
ORS–Output Record Separator
与FS和OFS的关系一样,ORS也是定义输出的行分隔符,默认情况下,awk使用换行符\n作为ORS,当然自定义的话也是可以的,比如
cat >employee.txt
101,John Doe,CEO
102,Jason Smith,IT Manager
103,Raj Reddy,Sysadmin
104,Anand Ram,Developer
105,Jane Miller,Sales Manager
awk 'BEGIN {FS=",";ORS="\n---\n";OFS=":"} {print $2,$3}' employee.txt
John Doe:CEO
---
Jason Smith:IT Manager
---
Raj Reddy:Sysadmin
---
Anand Ram:Developer
---
Jane Miller:Sales Manager
---
NR — Number of Records
当放在主体语句中,这个内置变量会给出当前行号;当放在END语句中,它会给出总行数,例如:
awk 'BEGIN {FS=","} \
{print "Emp Id of record number",NR,"is",$1;} \
END {print "Total number of records:",NR}' employee.txt
END {print "Total number of records:",NR}' employee.txt
Emp Id of record number 1 is 101
Emp Id of record number 2 is 102
Emp Id of record number 3 is 103
Emp Id of record number 4 is 104
Emp Id of record number 5 is 105
Total number of records: 5
刘小泽写于19.5.4 这次来看看AWK的各种运算操作符以及条件判断
示例文件
文件一
新建一个文件,有4列:员工ID、姓名、职位、薪水
cat >employee-sal.txt
101,John Doe,CEO,10000
102,Jason Smith,IT Manager,5000
103,Raj Reddy,Sysadmin,4500
104,Anand Ram,Developer,4500
105,Jane Miller,Sales Manager,3000
下面可以输出每个人的薪水,并且计算总共发放的薪水
awk -F, 'BEGIN {total=0} {print $2 " salary is: " $4; total+=$4} END {print "---\nTotal company salary = $"total}' employee-sal.txt
John Doe salary is: 10000
Jason Smith salary is: 5000
Raj Reddy salary is: 4500
Anand Ram salary is: 4500
Jane Miller salary is: 3000
---
Total company salary = $27000
文件二
cat >items.txt
101,HD Camcorder,Video,210,10
102,Refrigerator,Appliance,850,2
103,MP3 Player,Audio,270,15
104,Tennis Racket,Sports,190,20
105,Laser Printer,Office,475,5
一元运算操作符 Unary Operators
一元运算具有一个参数
| 操作符 | 描述 |
|---|---|
| + | 返回数字本身 |
| - | 相反数 |
| ++ | 累加 |
| – | 累减 |
比如要对某一列数字取相反数,直接在这一列的变量前面加-即可
awk -F, '{print -$4}' employee-sal.txt
-10000
-5000
-4500
-4500
-3000
关于累加、累减的符号方向问题:
如果将
++或者—放在变量名之前,它会先把这一列数字全部加一或减一,再输出awk -F, '{print ++$4}' employee-sal.txt 10001 5001 4501 4501 3001如果放在变量名之后,会先输出,再全部加一或减一
# 如果只这样输出的话,只会先输出计算之前的 awk -F ',' '{print $4++}' employee-sal.txt 10000 5000 4500 4500 3000 # 如果想输出计算后的,那么就需要再print一下 awk -F ',' '{$4++; print $4}' employee-sal.txt 10001 5001 4501 4501 3001
记做:
++或--在前,先输出;在后,后输出
字符串操作符
主要使用空格,将两个字符串连接起来。中间空格数量不限,保证至少有一个,另外=前后也是可以有空格的,这个不影响
例如:
awk 'BEGIN{str1="Bioinfo"; str2="planet"; str3=str1 str2; print str3}'
Bioinfoplanet
逻辑运算
处理> <以外,判断等于用==,不等于用!= ,表示且用&&,或用||
使用逻辑值判断时,默认将符合条件的全行输出,如:
# 小于等于
awk -F "," '$5 <= 5' items.txt
102,Refrigerator,Appliance,850,2
105,Laser Printer,Office,475,5
# 等于
awk -F "," '$1 == 103' items.txt
103,MP3 Player,Audio,270,15
#满足条件指定输出其他项
awk -F "," '$1 == 103 {print $2}' items.txt
MP3 Player
# 不等于
awk -F "," '$3 != "Video"' items.txt
102,Refrigerator,Appliance,850,2
103,MP3 Player,Audio,270,15
104,Tennis Racket,Sports,190,20
105,Laser Printer,Office,475,5
# 多个逻辑判断 &&
awk -F "," '$4 < 900 && $5 <= 5' items.txt
102,Refrigerator,Appliance,850,2
105,Laser Printer,Office,475,5
# 多个判断后指定输出
awk -F "," '$4 < 900 && $5 <= 5 {print $2}' items.txt
Refrigerator
Laser Printer
# 使用||判断d
awk -F "," '$4 < 900 || $5 <= 5 {print $2}' items.txt
正则表达
当使用==时,awk会从头到尾检查一遍,只有全部满足条件的,才可以输出
比如:
awk -F, '{print $2}' items.txt
HD Camcorder
Refrigerator
MP3 Player
Tennis Racket
Laser Printer
如果这里要挑出带有Laser的,使用awk -F "," '$2 == "Tennis"' items.txt 就没有结果,这时就要用到匹配操作符~
awk -F "," '$2 ~ "Laser"' items.txt
105,Laser Printer,Office,475,5
与之相反的是!~ ,表示不包含
awk -F "," '$2 !~ "Laser"' items.txt
条件判断
一般使用:
- Simple If statement
- If-Else statement
第一种简单的if判断
if (条件判断) 操作,并且可以支持多个操作,放在一个大括号中就好if (条件判断) {操作1;操作2}
比如输出items文件中最后一列数量小于等于5的
awk -F, '{if ($5<=5) print "Only",$5,"qty of",$2, "is available"}' items.txt
Only 2 qty of Refrigerator is available
Only 5 qty of Laser Printer is available
再复杂一点,找到第四列的价位在500~1000之间,并且数量小于5的
awk -F, '{if (($4>=500 && $4<=1000) && ($5<=5)) print "Only",$5,"qty of",$2,"is available"}' items.txt
Only 2 qty of Refrigerator is available
第二种 if-else
大体操作就是
if (条件判断,可以有多个,其中每个判断都要写在小括号中)
操作1
else
操作2
循环
While循环
简单的while模式,例如
awk 'BEGIN \ { while (count++<50) string=string "x"; print string }'do-while循环,使用
do action while(condition)的结构,例如awk 'BEGIN {count=1;do print "At least once"; while(count!=1)}'
For循环
它的语法是这样的:
for(initialization;condition;increment/decrement)
actions
比如:
echo "1 2 3 4" | awk \
'{ for (i = 1; i <= NF; i++) total = total+$i }; \
END { print total }'
# 结果就是累加值 10
刘小泽写于 AWK额外的命令
printf
printf让输出结果过程变得更简单,语法就是:
printf "print format", variable1, variable2, etc.
其中print format可以包含\n,\t等

比如:
awk 'BEGIN { printf "Line 1\nLine 2\n" }'
Line 1
Line 2
增加于19.6.23
awk中间是循环体,最后END返回的才是结果
例如:
awk '{print NR}'
awk 'END{print NR}'
# 看它们的差别,带END的只会返回总行数